Experiments on common benchmarks
In the last experiment, we evaluate our learning algorithm on commonly used benchmarks.
The source code and data are available in the changelog, which is actively maintained.
INRIA person
In the following two figures, we compare HIT with the state-of-art HoG on INRIA person dataset.
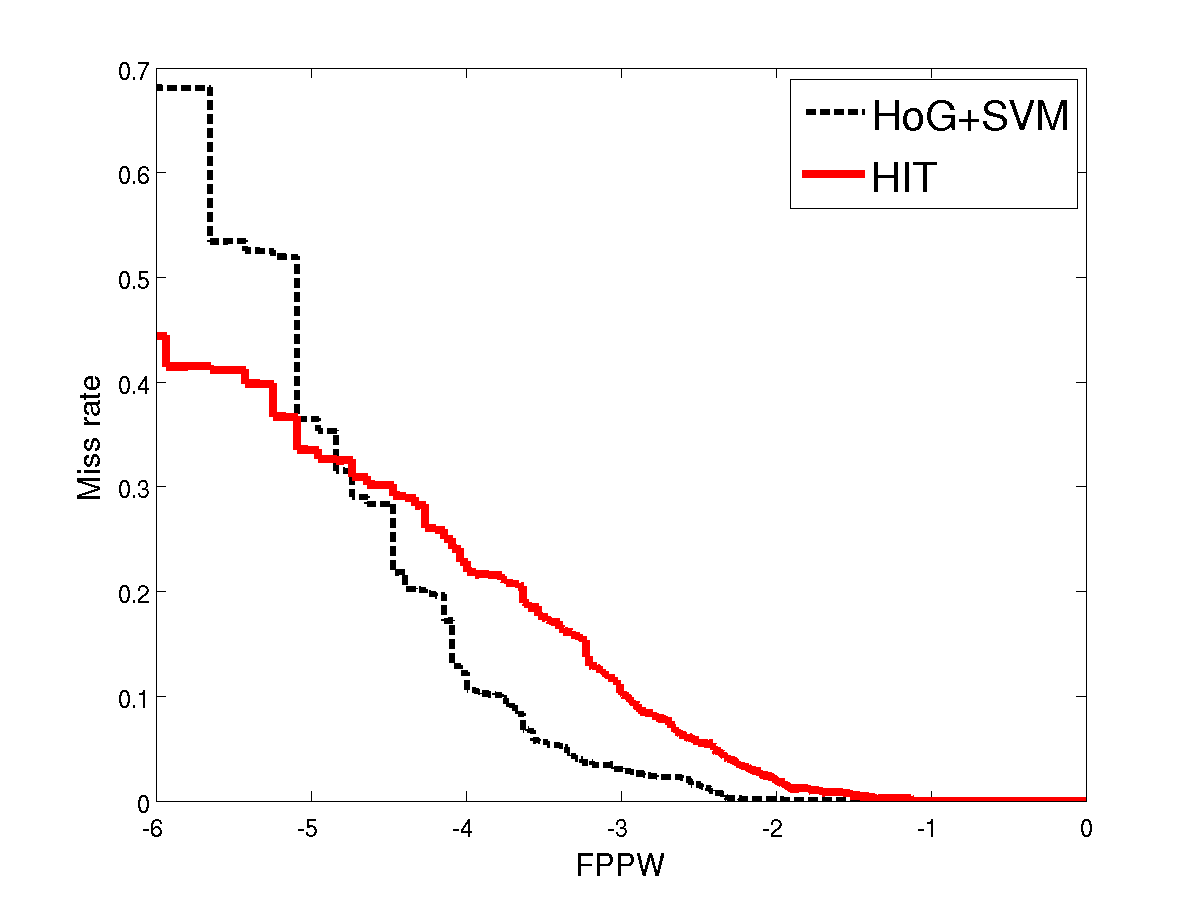
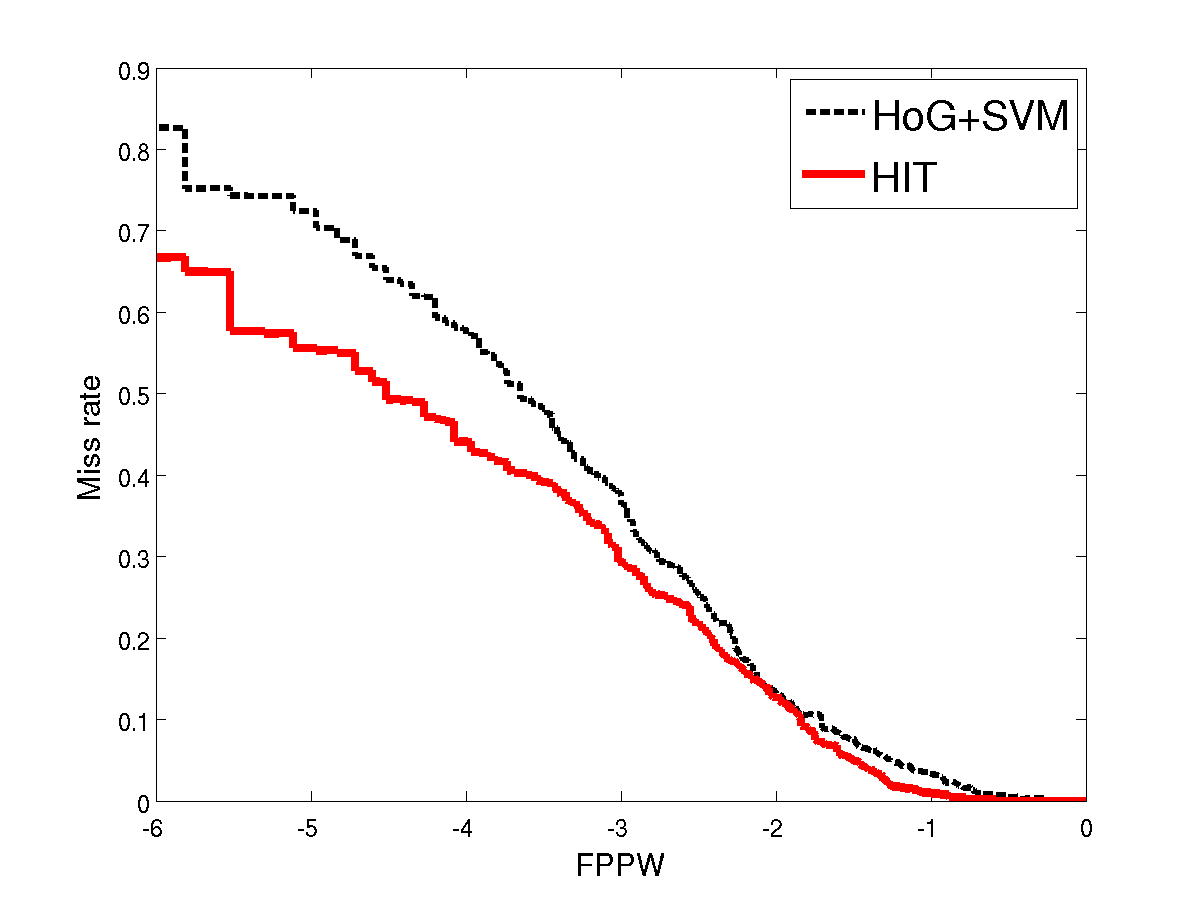
The left figure corresponds to training using all 2416 training positives, and the right figure corresponds to training with only the first 100 positive examples. The negative patches are sampled according to the description at the project page of Dalal&Triggs '05. Both positive and negative image patches are of size 134 by 70 pixels, and they are cropped from original images before feature maps are computed from them. In this way, we make sure that boundary effect is not used unfairly in favor of any training algorithm. Following Dalal&Triggs '05, we use the metric of miss rate plotted against the logarithm of FPPW (false positive per window). The lower curve indicates smaller miss rate and better performance. In the standard setting of training size, HIT is on par with HoG and performs much better than HoG at very low false positive rate (e.g. 1e−6 ). While using a small training size, HIT has a lower miss rate than HoG for the whole range of FPPW.
PASCAL VOC 2007
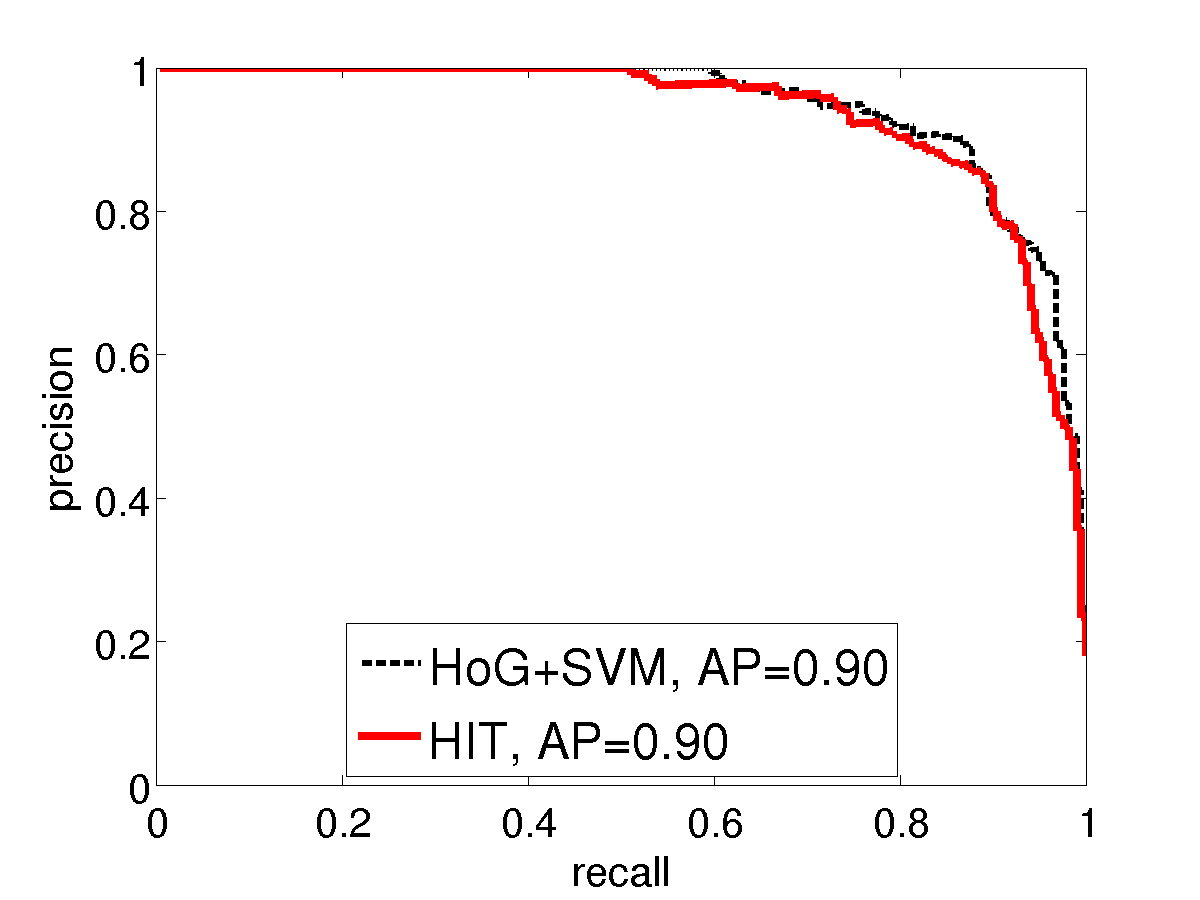
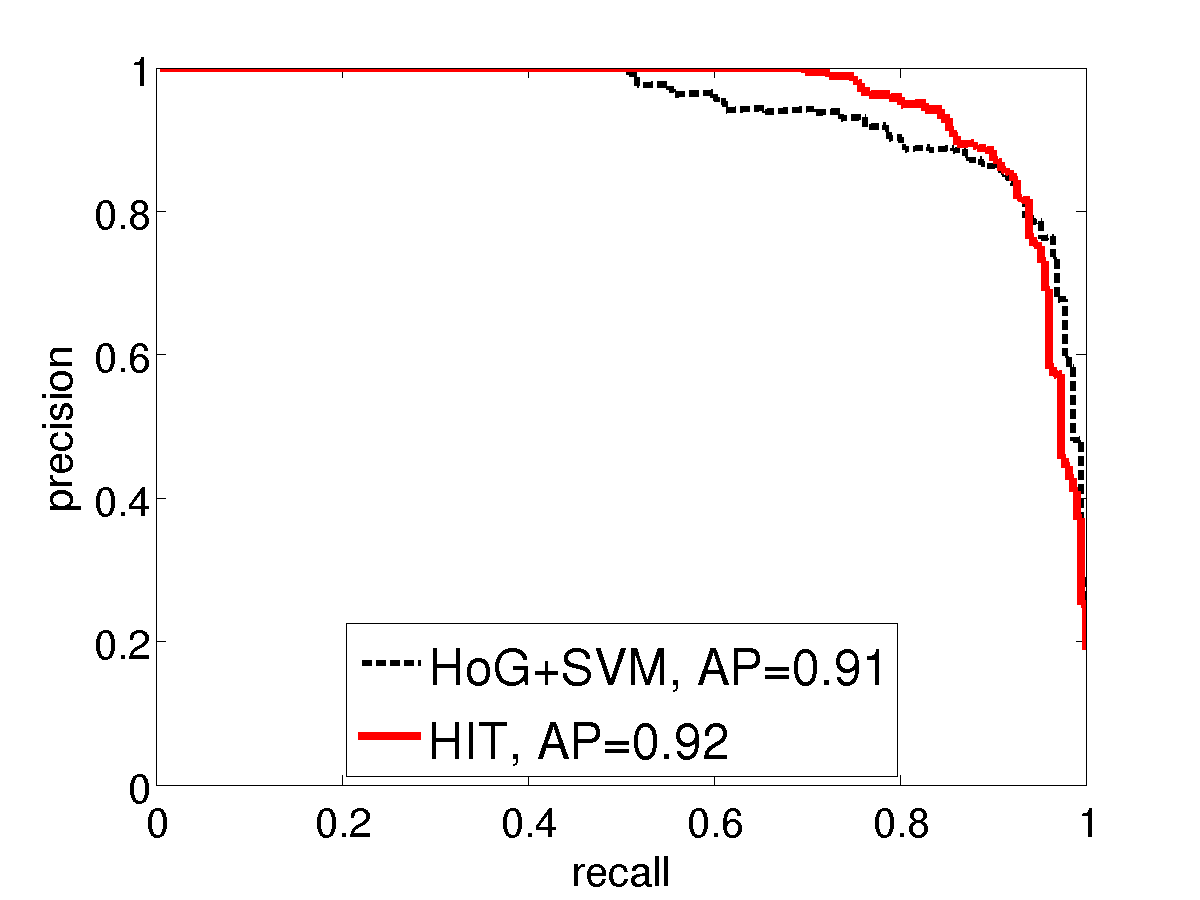
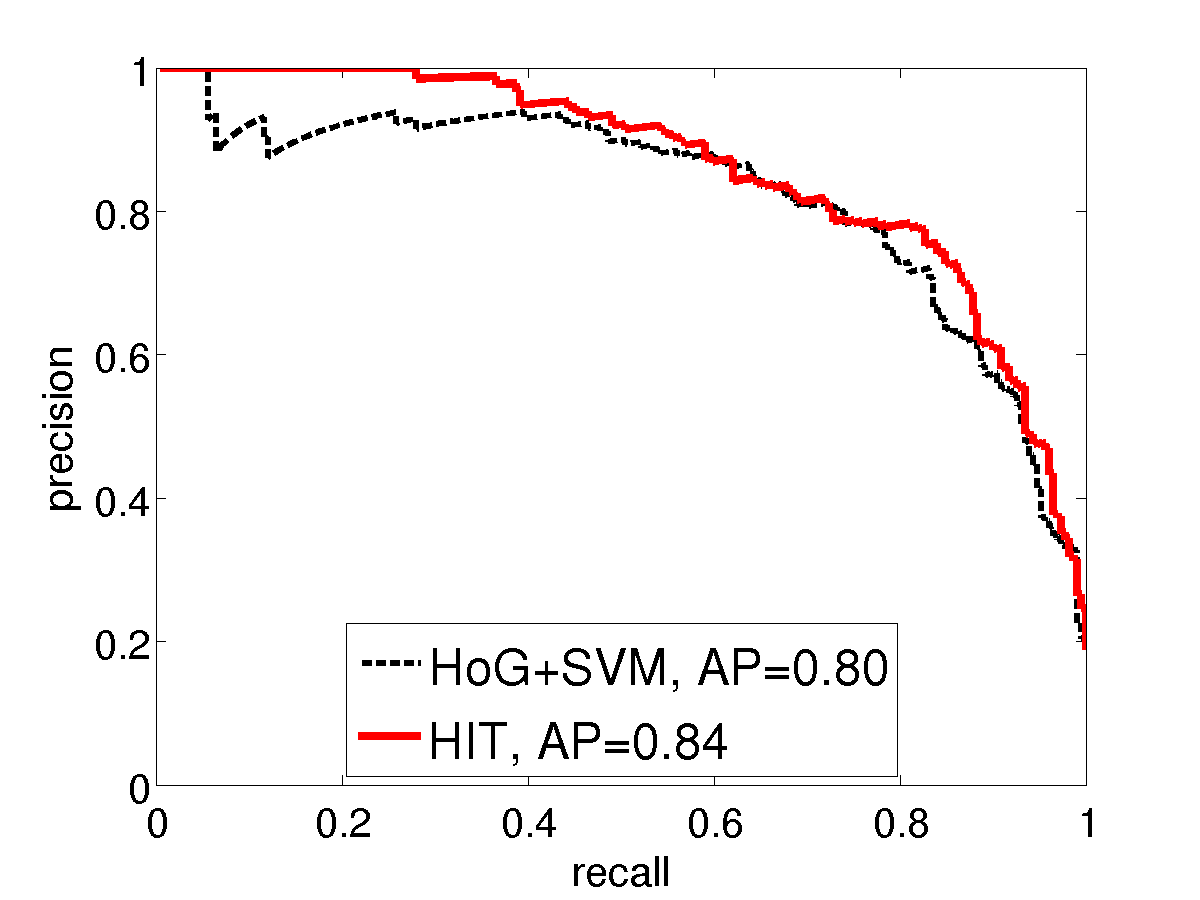
We compare with HoG using precision-recall curves on two Pascal VOC2007 categories: bike and horse. Similar to the INRIA person experiment, we use two settings of training sample sizes. For standard training size (the left sub- figures), we use all the 241 horse and 139 bike images in TRAINVAL. For small training size (the right sub-figures), we only use the first 20 positive examples. The images in TEST (232 horse and 221 bike images) are used as testing positives. We collect the positive examples by cropping a square patch around the bounding box annotation with a 10% margin and resizing them to 150x150 pixels. For negative examples, we use 150x150 patches cropped from background images as in our INRIA person experiment. It is observed that the performance of HIT is on par with HoG using all training positives. While using fewer training examples, HIT wins over HoG with a big margin.
VOC bike:
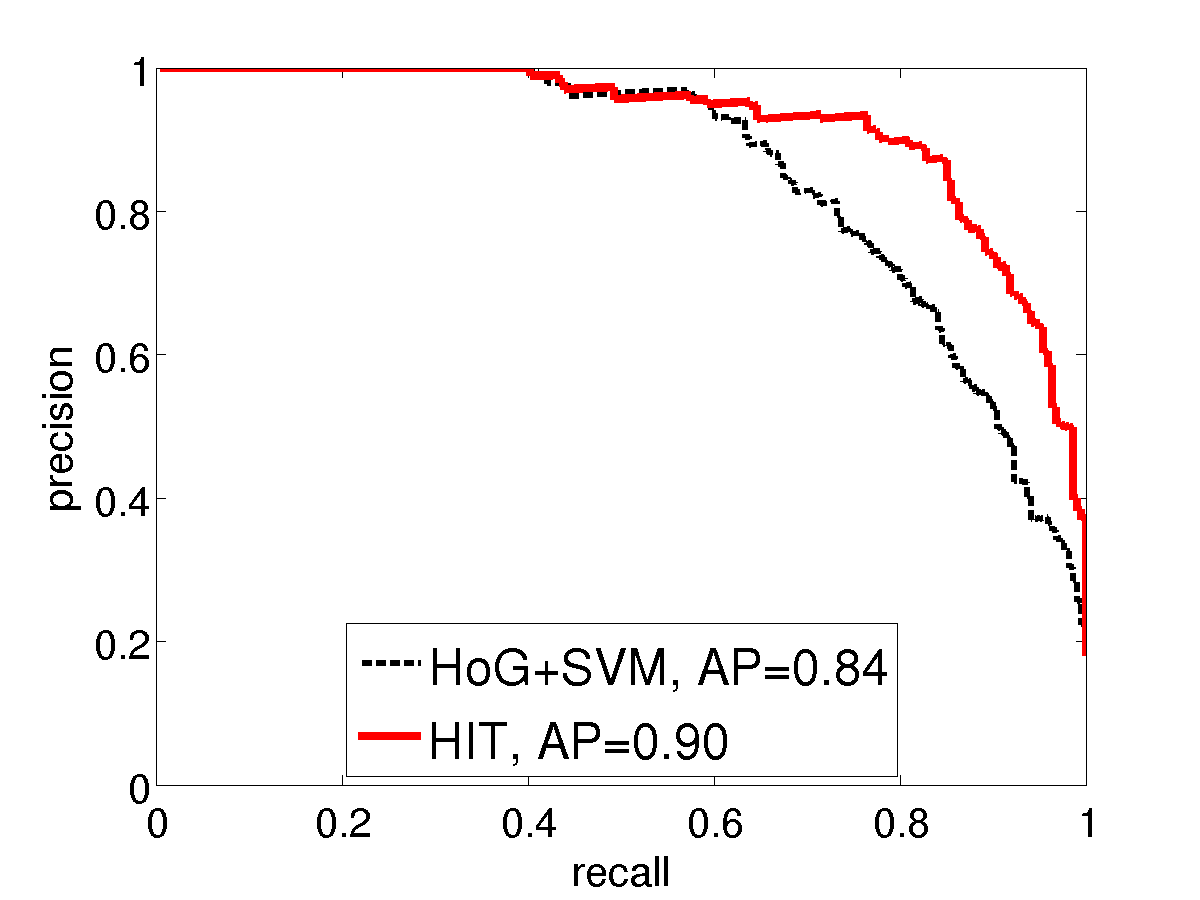
VOC horse:
Categorization on Caltech-101
Caltech-101 is one of the most popular dataset that object classification systems are tested on. The HiT templates are learned in a translational invariant fashion: during template learning, a hidden variable that accounts for unknown object location needs to be inferred for each image. For every category, we perform Expectation-Maximization for 10 iterations, with initialization that all objects are located in the center. To deal with different aspect ratios of the images, we "inscribe" all images inside a square of 150 by 150 pixels with coinciding centers.
The figure below lists a subset of templates learned from Caltech-101 dataset, with 15 training images per category. Though both sketch and texture features are used, for illustration purpose we only show the sketch features, and their deformation on example images. AUC (area under ROC curve) measures are shown on the right. The translational invariant template is able to detect itself and find its detailed correspondences in images, despite object deformation and uncertain location (e.g. faces). AUC is shown on the right with comparison to HoG feature. The translational invariant template is able to detect itself and find its detailed correspondences in images, despite object deformation and uncertain location (e.g. faces).
