Learning pairwise contrast templates
The figure at the bottom of this page is generated from the learning results of hybrid image templates, produced by codes in the following ZIP file. Please see README.txt for how to generate main parts of this figure.
What is in common and what is different between tomato and pear or between cats and wolves? It is interesting to study the "pair-wise contrast template" which can be used to discriminate between the two categories.
Setting: Suppose we are given two datasets D_1 and D_2 for the two categories C_1 and C_2 respectively. Let HiT_1 and HiT_2 be the two learned HiT templates from D_1 and D_2 respectively against a generic reference model q. Here we compare two ways for learning the contrast templates HiT_{1-2} and HiT_{2-1}.
In method A, we replace the generic reference model q by the category that we are discriminating from. In the learning process, the information gain for any common part (patch) between the two categories is reduced, and thus the learned contrast templates emphasize the differences. This is, in fact, equivalent to the direct subtraction of the two templates except that the stopping criterion need to be adjusted and the parameters (\lambda_k, z_k) need to be re-calculated. In method B, we take the union of the two sets of patches and prototypes from HiT_1 and HiT_2 and re-weight them by a SVM discriminative learning process.
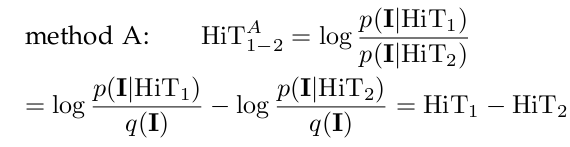
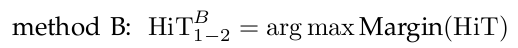
The following illustration shows two pair-wise contrast templates: cat vs. wolf, and cat vs. dog. We can see that, by contrasting generative models of different image categories, we can already obtain reasonable one-vs-one classifiers similar to the ones discriminatively trained. This explains why hybrid image templates can work for image categorization.
