Weakly supervised clustering of HiT's
In this experiment we are interested in the learning and classification of hybrid image templates in the context of weakly supervised learning and clustering. The dataset used in this experiment is the LHI-Animal-Faces dataset, some of which are shown below:

The LHI-Animal-Faces dataset is a good dataset for visual learning and classification, because the animal face categories exhibit interesting within-class variation and between-class confusion. The within-class variation includes: (1) rotation and flip transforms, e.g. rotated panda faces and left-or-right oriented pigeon heads; (2) posture variation, e.g. rabbits with standing ears and relaxed ears; and (3) sub-types, e.g. male and female lions. The between-class confusion is mainly caused by shared parts: wolves and cats both have sharp ears at roughly the same positions; sheep and cow faces share a similar contour.
We run two experiments on this dataset. In the first part, we learn one translation-invariant template per category, and the learned HiT's are shown below:


In the second part, we learn three HiT templates per category to account for more within-class variation. This is done through an EM algorithm and the mixed template are then translation, rotation and reflection (flip)-invariant. We use both sets of HiT's for classification between the 20 categories. For a testing image, we compute the log likelihood scores of all 20 (or 20*3 in the case of 3 templates per category) templates, and the label is determined by the template with the highest score. The following figure shows several distinct clusters of animal face images automatically obtained by the algorithm. Each cluster is modeled by one HiT template, which is invariant to translation, rotation and reflection. For example, the ducks in Figure~\ref{fig:animal face matching} facing left and right are identified as the same object category and described by one HiT. For illustration purpose only sketch features of the template are shown. Particularly note that the two types of rabbit head images with standing ears vs. with relaxed ears are automatically discovered by our learning algorithm with an EM-like procedure.






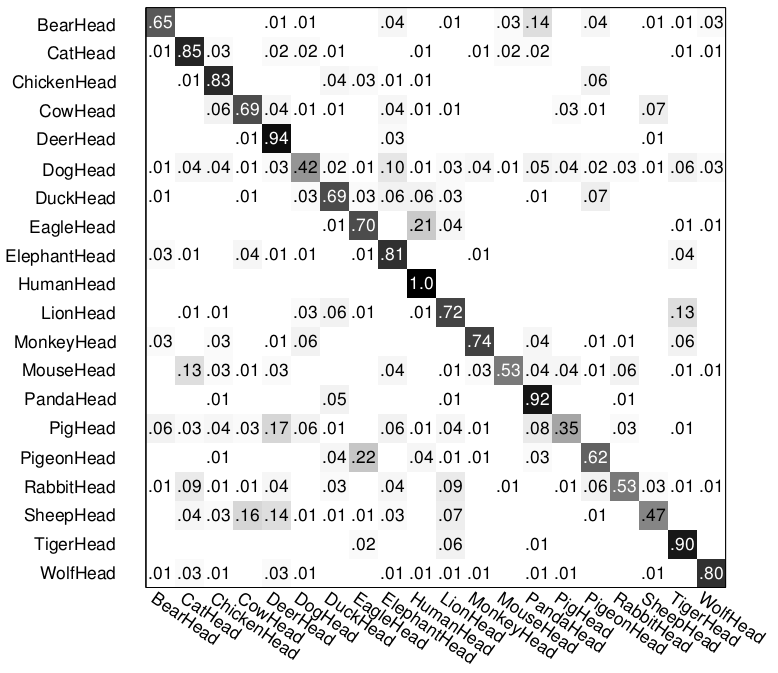
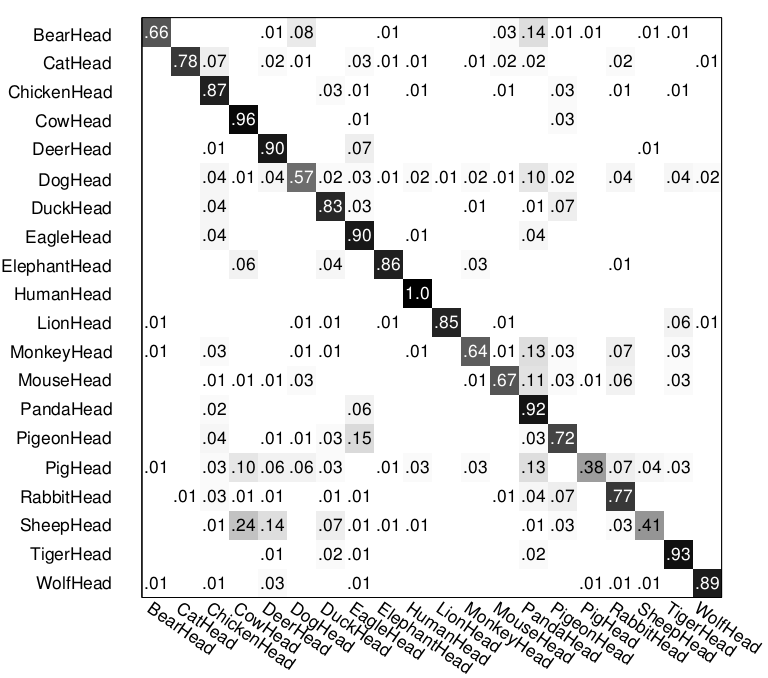
The following figure shows the confusion matrices in both cases. By adding rotation/reflection invariance and clustering during learning process, we are able to improve the multi-class recognition accuracy from 0.72 to 0.76. Notice that in the second confusion matrix, the top two confusions are caused by sheep head vs. cow head, and pigeon head vs. eagle head.
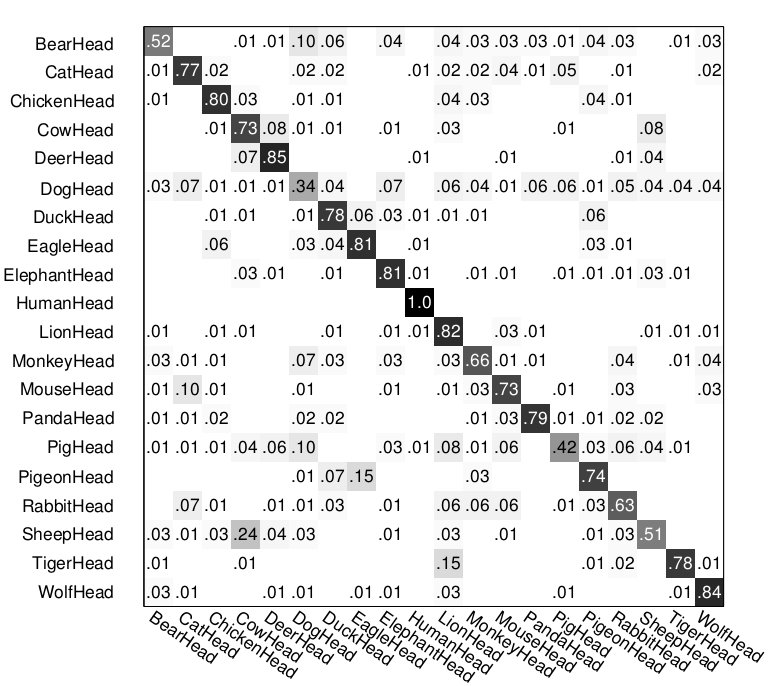
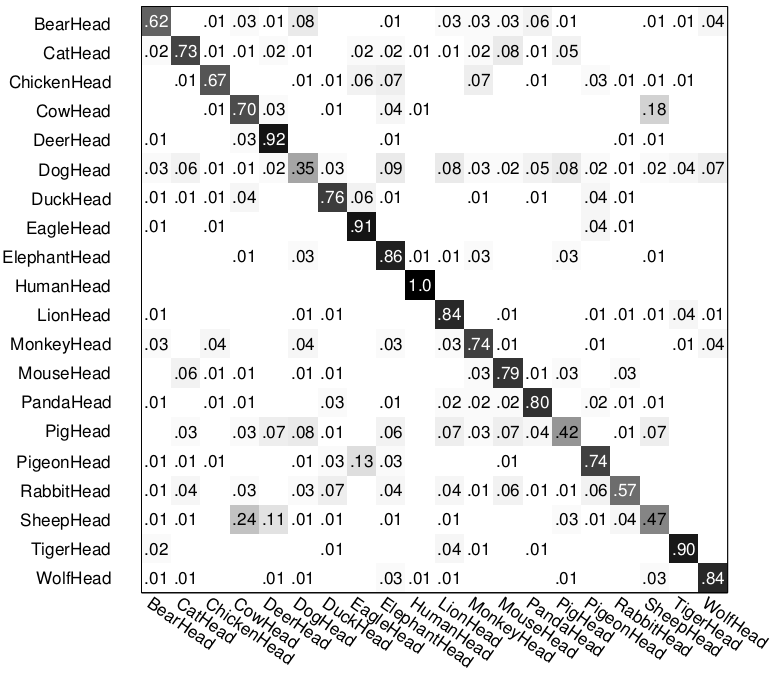
We compare with two state-of-art systems: HoG+SVM by Dalal & Triggs and part-based latent SVM by Felzenszwalb et. al., whose confusion matrices on the same training/testing split are shown below. In particular, HoG+SVM recognizes the animal faces with an accuracy of 0.71, while part-based latent SVM is able to get 0.78. Note that HIT is not a part based model as its constituent components are atomic (e.g. small sketches).