Introduction
Cloth modeling and recognition is an important and challenging problem in both vision and graphics tasks, such as dressed human recognition and tracking, human sketch and portrait. In this work we construct context sensitive grammar using an And-Or graph representation which can produce a large set of composite graphical templates to account for the wide variabilities of cloth configurations such as T-shirts, jackets, etc. We decompose hand labeled sketches into categories of cloth and body components: collars, shoulders, cuff, hands, pants, shoes etc. Each component has a number of distinct subtemplates (sub-graphs). These sub-templates serve as leaf nodes in a big And-Or graph where an And-node represents a decomposition of the graph into sub-configurations with Markov relations for context and constraints (soft or hard), and an Or-node is a switch for choosing one out of a set of alternative And-nodes (sub-configurations) – similar to a node in stochastic context free grammar (SCFG). This representation integrates the SCFG for structural variability and the Markov (graphical) model for context. An algorithm which integrates the bottom-up proposals and the top-down information is proposed to infer the composite cloth template from the image.Approach
There are three major challenges in representing cloth.
1. Geometric deformations: clothes do not have static
form and are very flexible.
2. Photometric variabilities: large variety of colors,
shading effects, and textures.
3. Topological configurations: a combinatorial number
of cloth designs – T-shirts, jackets, pockets, zips, suits,
sweaters, coats where cloth components may be reconfigured
and combined to yield new styles.
We adopt a sketch graph representation similar to the primal sketch to represent shape outlines, occlusion boundaries, folds in clothes, and occlusion boundaries. The geometric deformations of clothes are accounted for by the flexibility of the sketch graphs, and the photometric variabilities are accounted for by the rich image primitives whose parameters control the photometric variations.
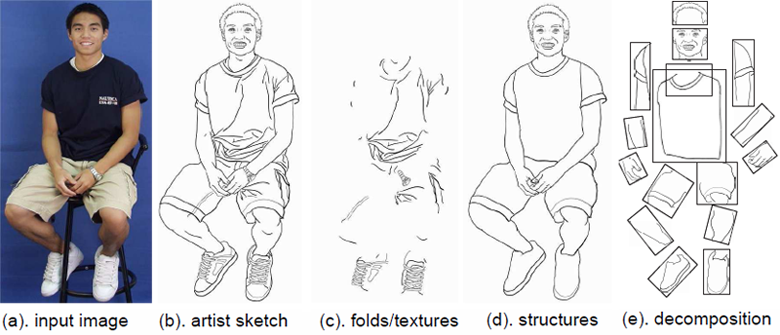 figure 1: the body model is trained from hand labeled sketches (b) that decompose the body into internal sketches (c), sketches that define the part structure (d), and a decomposition of the structure into parts (e).
figure 1: the body model is trained from hand labeled sketches (b) that decompose the body into internal sketches (c), sketches that define the part structure (d), and a decomposition of the structure into parts (e).
And-Or Graph Model
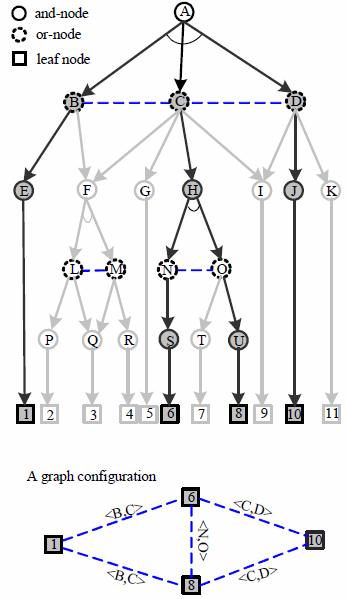 figure 2: the And-Or graph is used to define the combinatorial variety of body configurations by selecting sub-configurations at the Or-nodes. A parse graph is an instantiation of the And-Or graph, and is created by choosing the switch variables at each Or-node. A graph configuration consists of only terminal nodes from a parse graph.
figure 2: the And-Or graph is used to define the combinatorial variety of body configurations by selecting sub-configurations at the Or-nodes. A parse graph is an instantiation of the And-Or graph, and is created by choosing the switch variables at each Or-node. A graph configuration consists of only terminal nodes from a parse graph.
Topological configurations are modeled by an And-Or graph grammar. Each terminal, or leaf node, represents a component or sub-templates. Different sub-templates in the same category are represented by distinct leaves. The non-terminal nodes are divided into And-nodes whose children must be chosen jointly and Or-nodes of which only one child can be selected to express the alternative components. Intuitively, an And-node expands the configuration and an Or-node is a switch between alternative sub-configurations. The And-Or graph should be distinguished from a tree because the graph has horizontal edges to specify the spatial relations and constraints among the components. A specific cloth configuration, say a jacket, corresponds to a subset of the And-Or graph. Thus one And-Or graph is like a "mother template" which produces a set of valid cloth configurations – "composite templates".
Attributes are defined on each node in the And-Or graph to describe photometric properties as well as spatial geometry such as location, scale, and orientation. The horizontal edges in the And-Or graph constrain the attributes of their corresponding sibling nodes, making the model a context-sensitive grammar.
Composite Templates
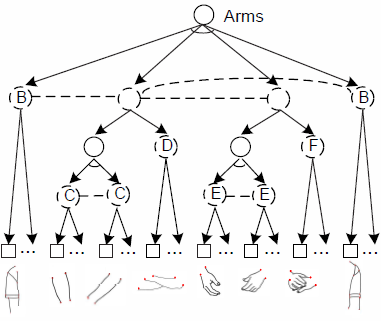 figure 3: And-Or graph for arm templates.
figure 3: And-Or graph for arm templates.
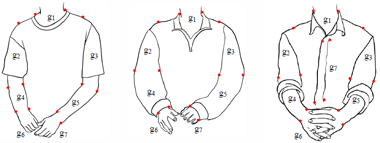 figure 4: three novel configurations of sub-templates drawn from the And-Or graph grammar.
figure 4: three novel configurations of sub-templates drawn from the And-Or graph grammar.
Inference and Results
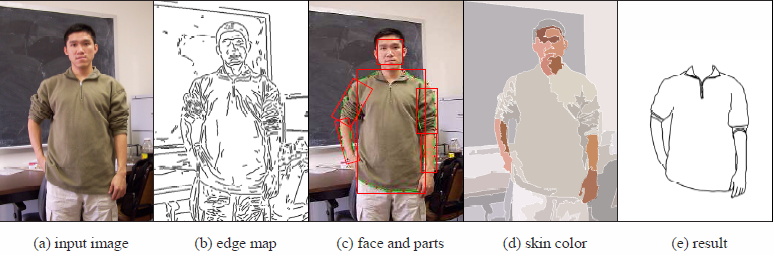 figure 5: Running example. (a) input image, (b) Canny edge map, (c) bottom-up detection of face and body parts, (d) skin color detection by mean-shift clustering in color space, (e) results of top-down matching.
figure 5: Running example. (a) input image, (b) Canny edge map, (c) bottom-up detection of face and body parts, (d) skin color detection by mean-shift clustering in color space, (e) results of top-down matching.
 figure 6: Recognition results of upper body with clothes. The input images are shown in the first row. The third row shows
the composite graphical templates inferred from the images. For comparison, the results of a canny edge detector are shown in the
middle row.
figure 6: Recognition results of upper body with clothes. The input images are shown in the first row. The third row shows
the composite graphical templates inferred from the images. For comparison, the results of a canny edge detector are shown in the
middle row.
Inference combines bottom-up and top-down search processes to infer a parse graph from an image. Bottom-up data driven proposals (discriminative tests) are designed for all nodes in the And-Or graph. Some nodes are more informative and thus can be detected more reliably, such as the face. Other nodes are less informative. For instance, the elbow is hard to infer when the arm is straight. It is also desirable to infer the nodes from coarse-to-fine. For example, the leaf nodes have many sub-templates which should be activated after their positions are located (predicted) from the parent nodes in the higher level of the And-Or graph. We carefully design the order of the bottom-up and top-down computation so that the more informative nodes are proposed and inferred earlier, and they in turn generate useful top-down/context information for computing the other less informative nodes.
References
Computer Vision and Pattern Recognition [pdf]