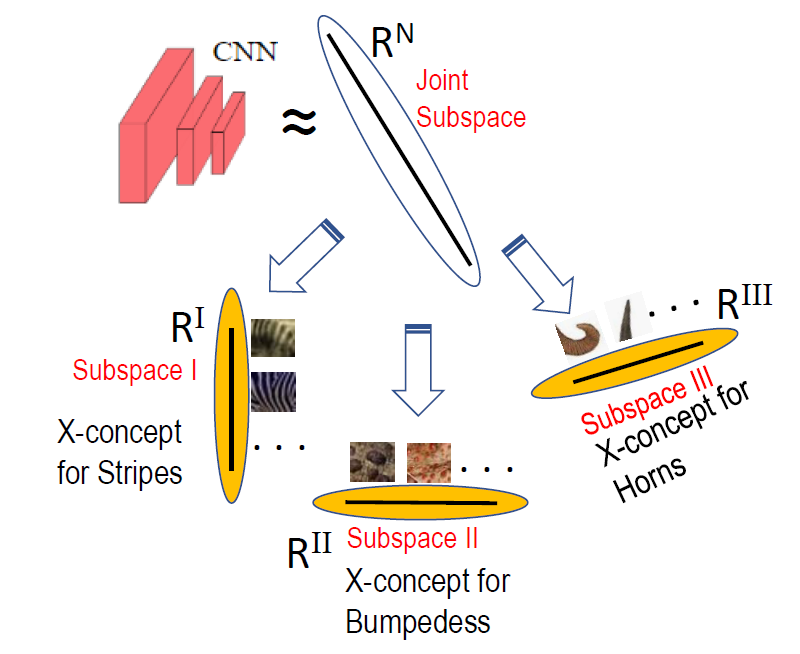
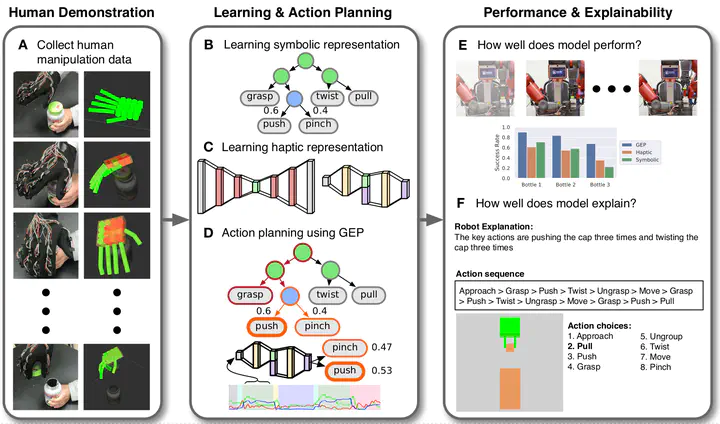
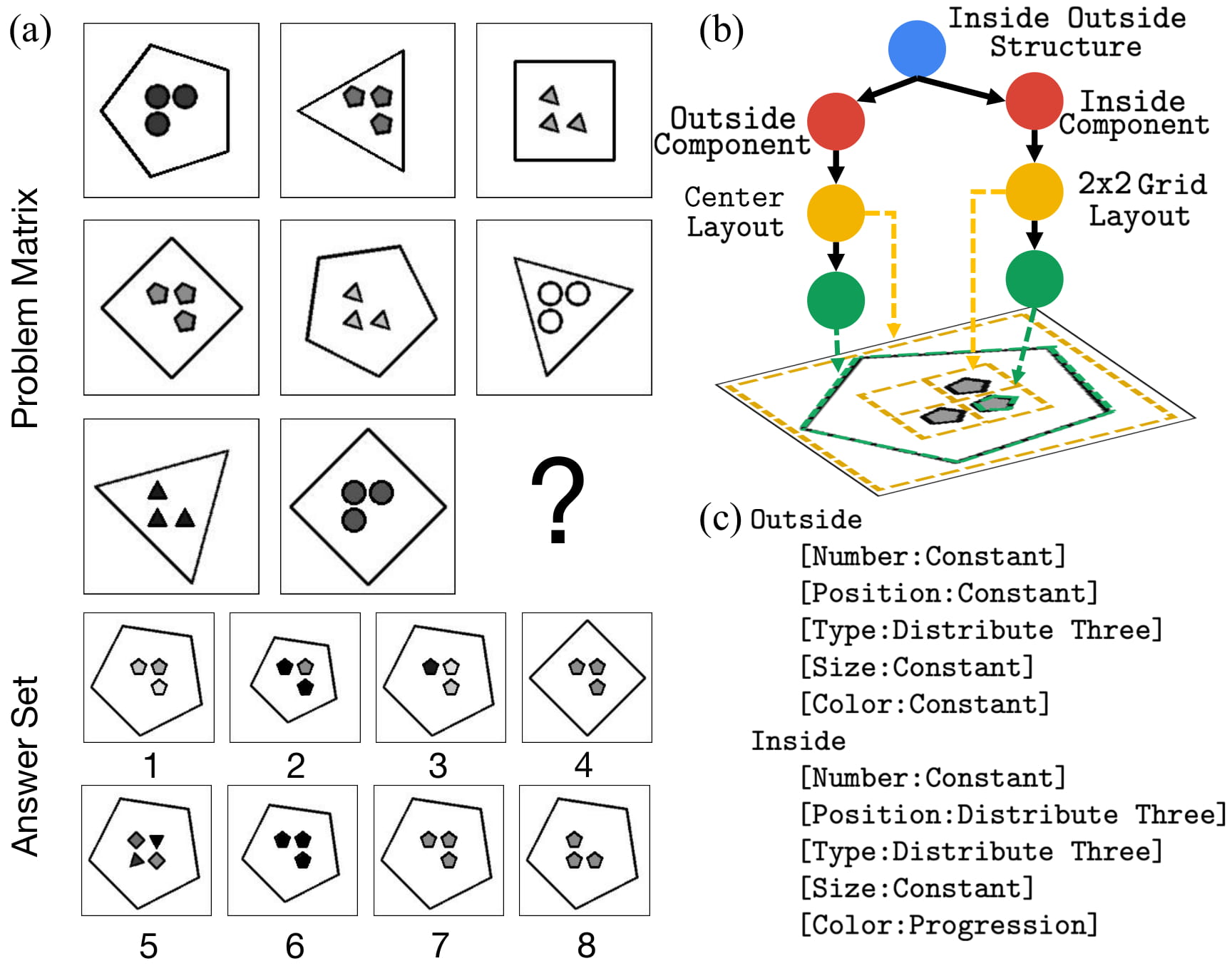
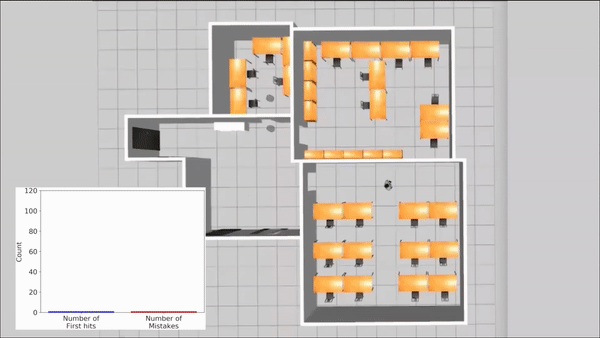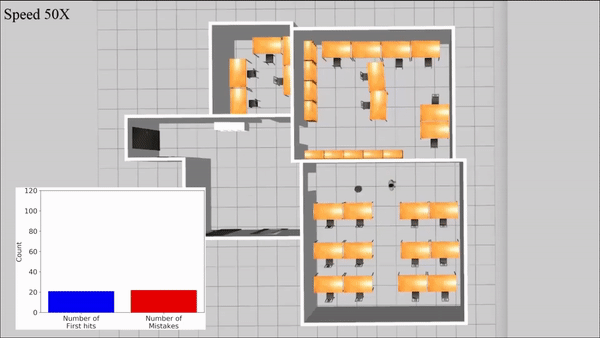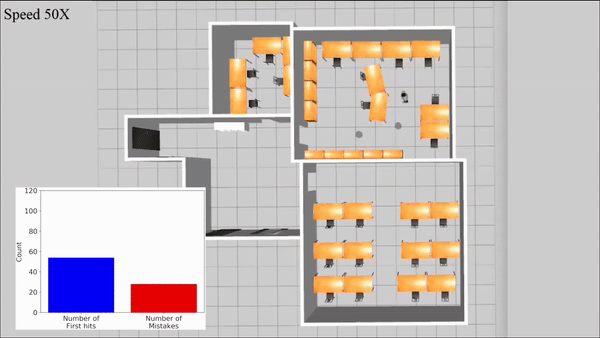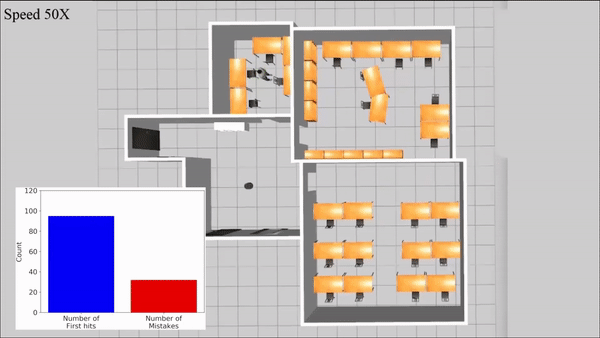
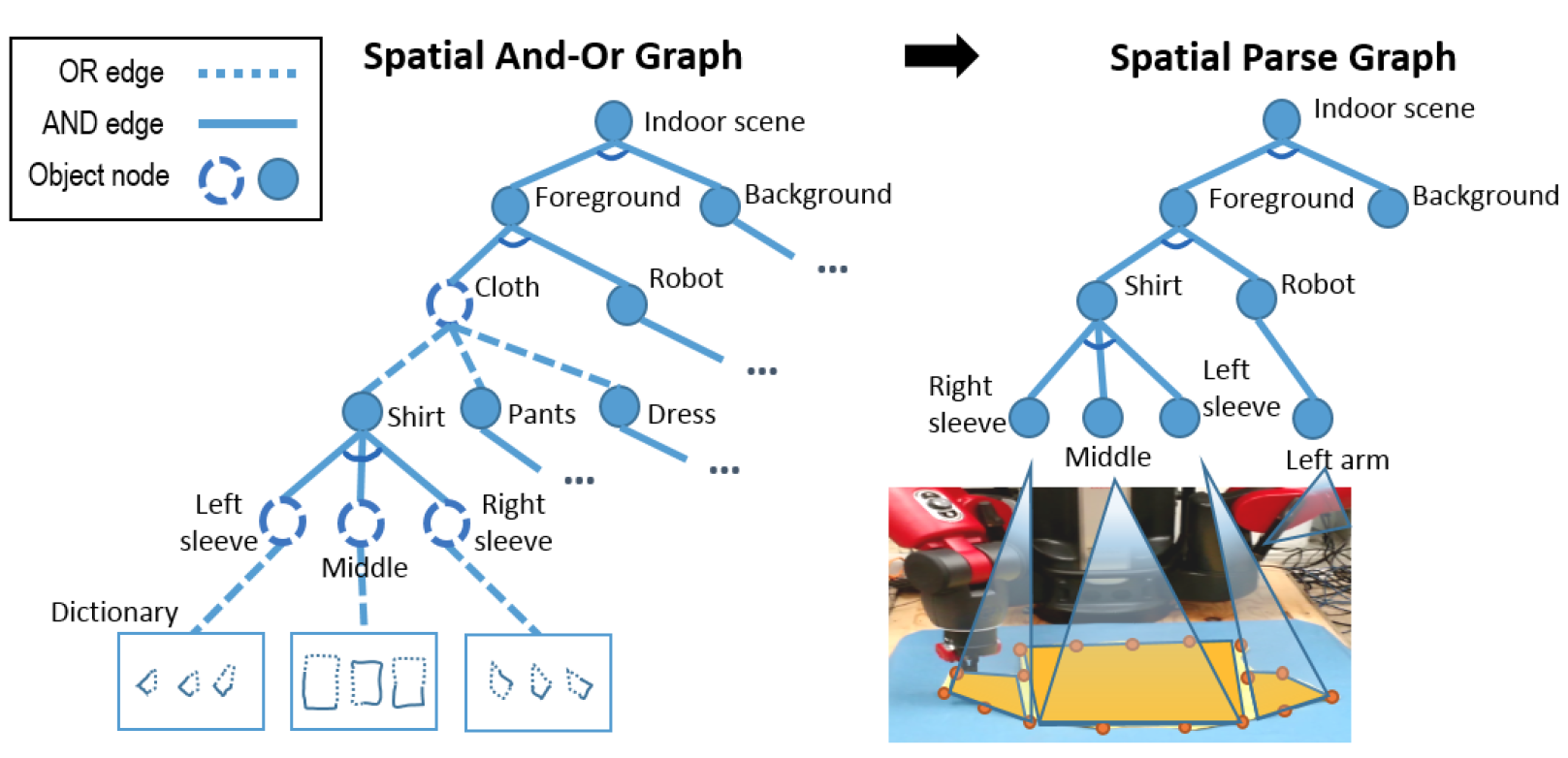
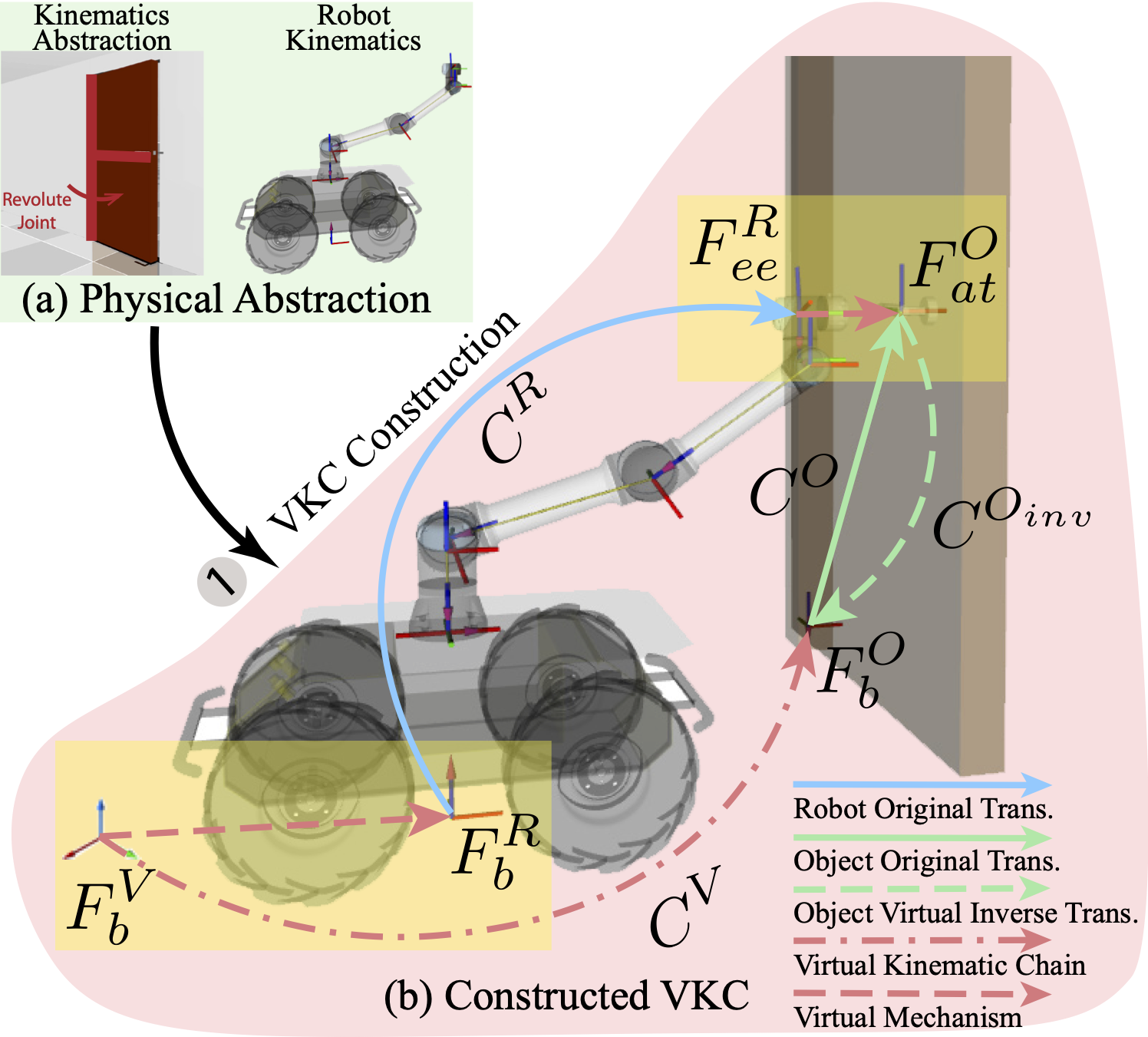
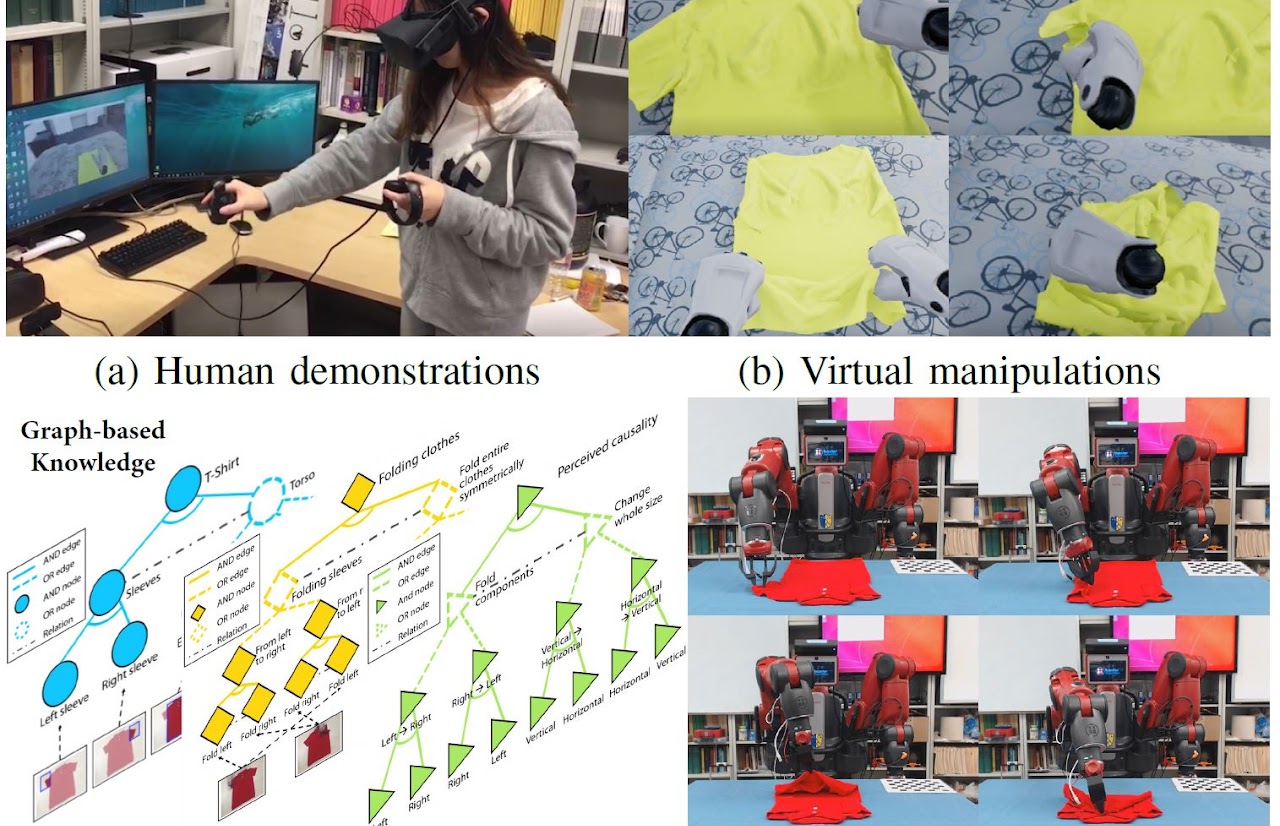
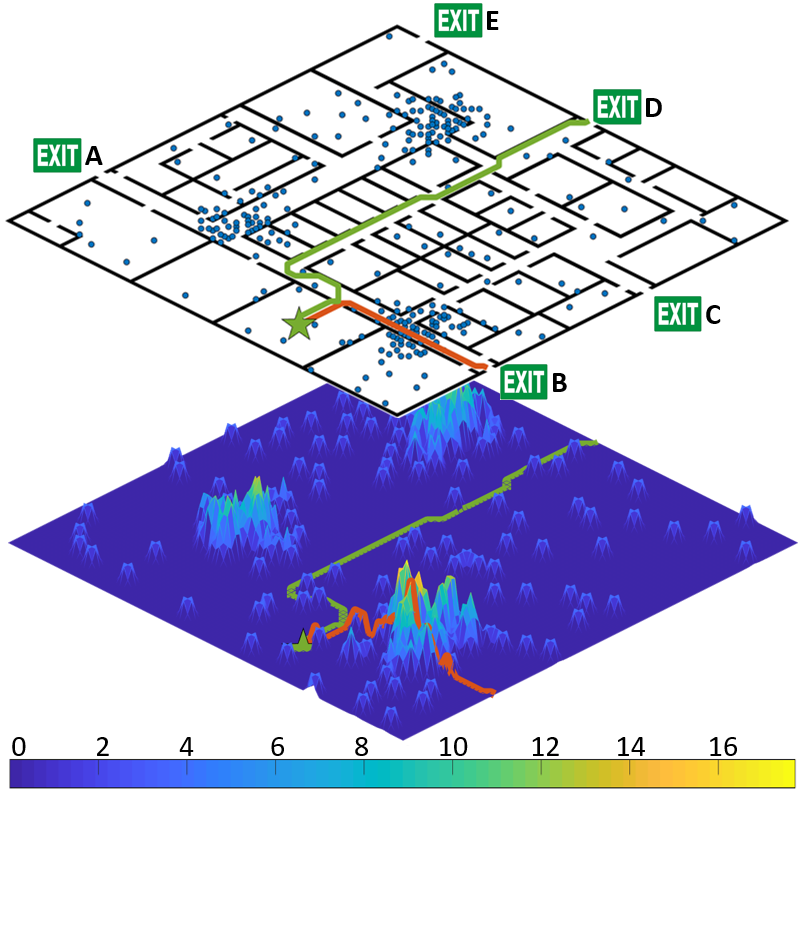
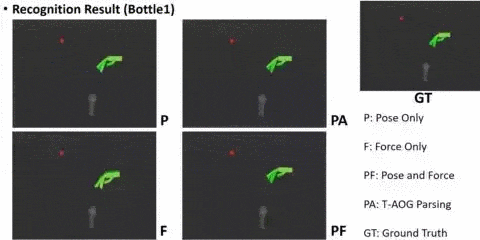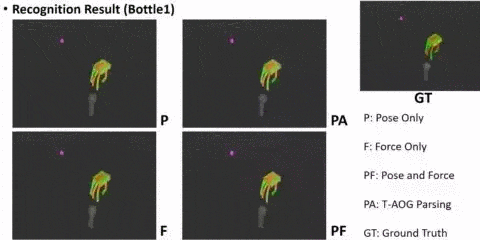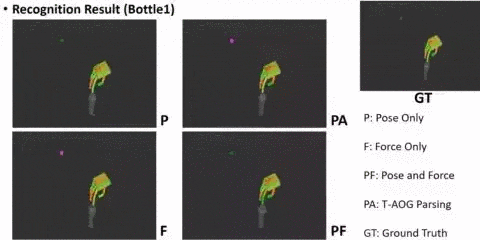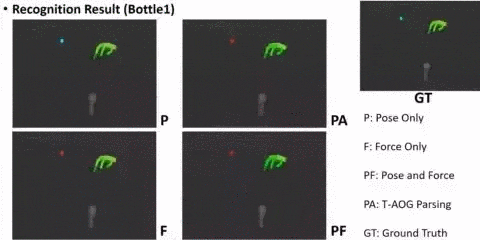
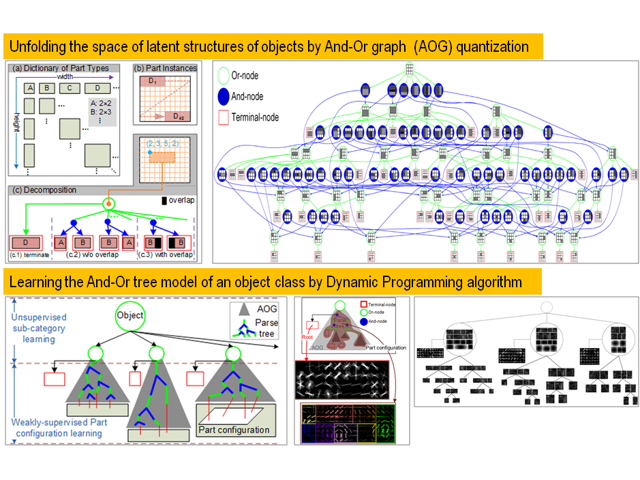
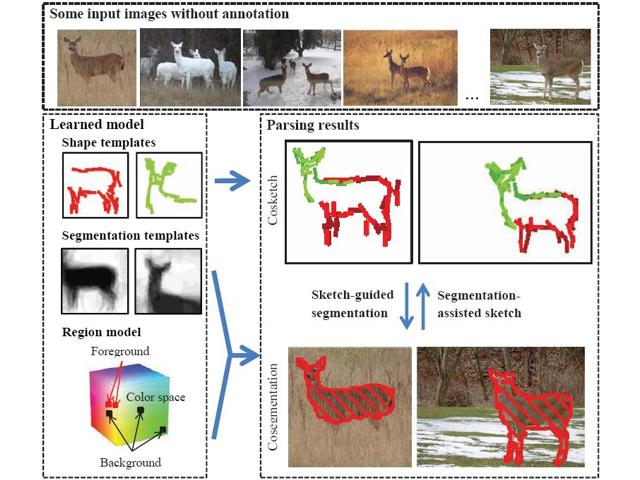
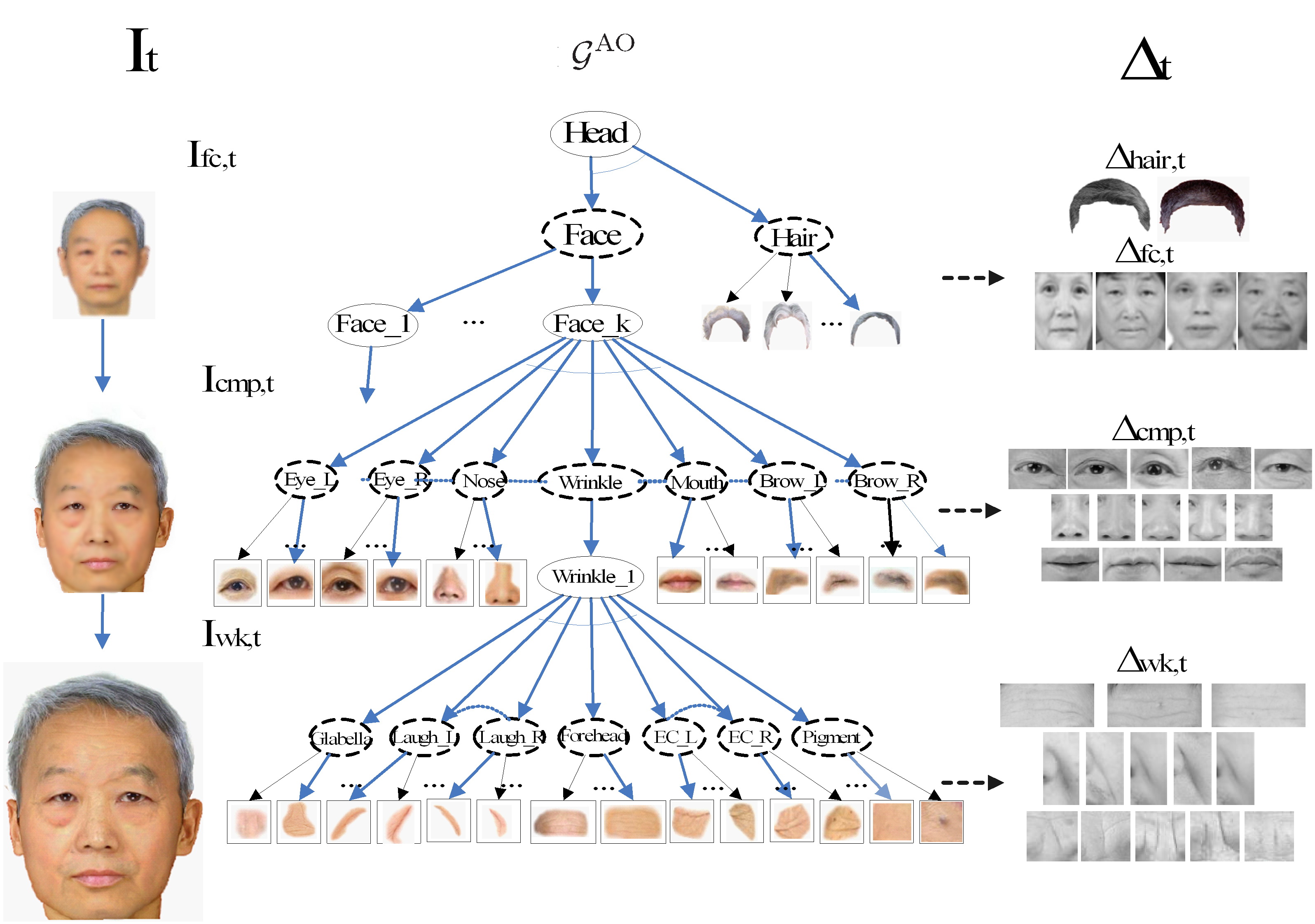
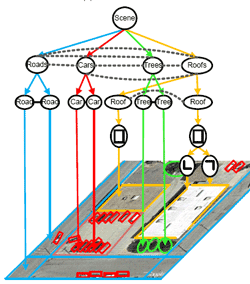
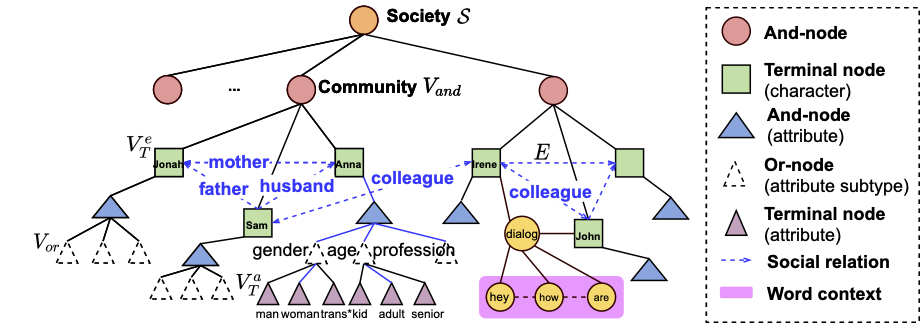
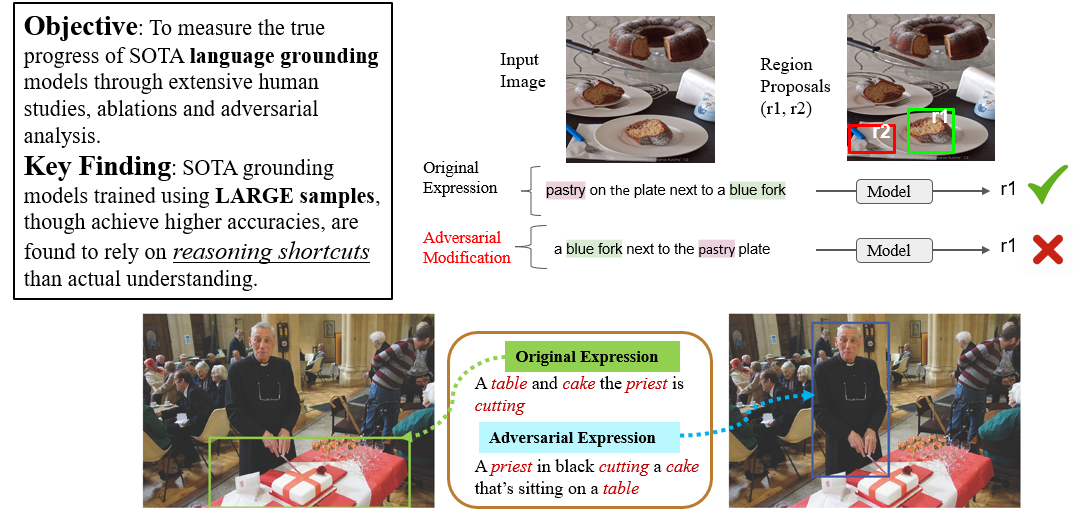
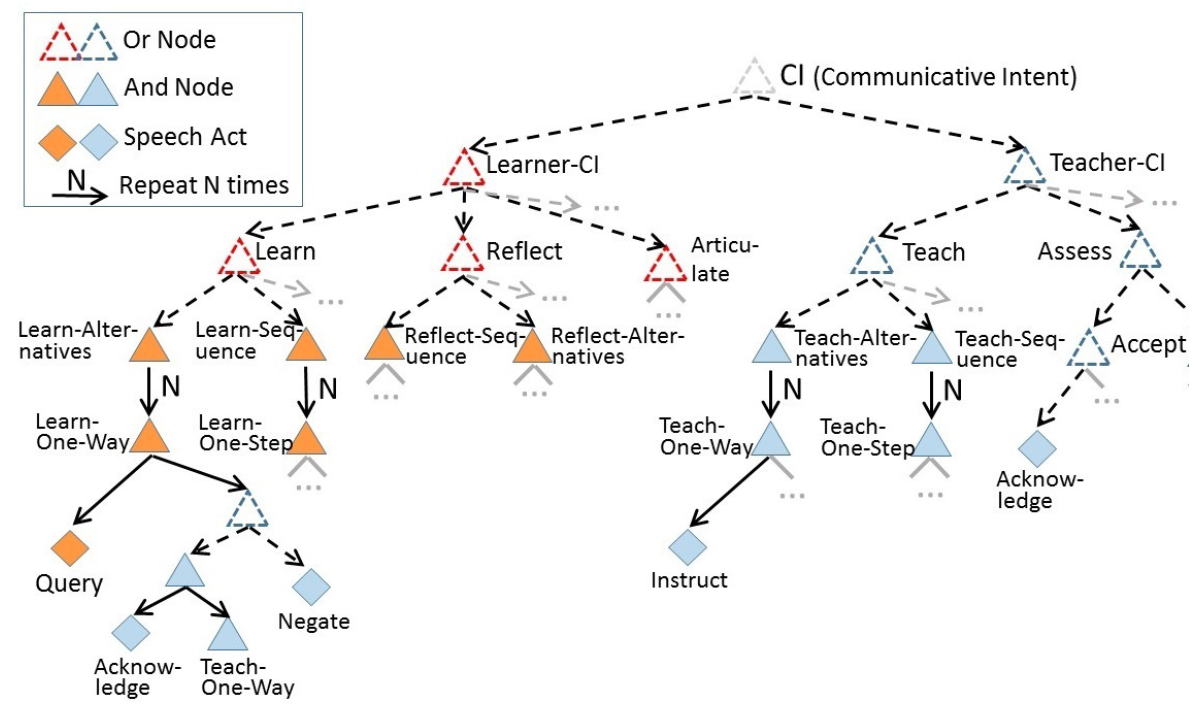
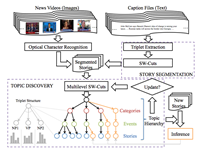
AI: Commonsense Reasoning, Multi-agent System, VR/AR Task Platforms
|
|
Sirui Xie,
Xiaojian Ma,
Peiyu Yu,
Yixin Zhu,
Ying Nian Wu, and
Song-Chun Zhu
|
|
|
|
|
Arjun Akula,
Changsong Liu,
Sari Saba-Sadiya,
Hongjing Lu,
Sinisa Todorovic,
Joyce Y Chai, and
Song-Chun Zhu
|
|
|
|
|
Wenhe Zhang,
Chi Zhang,
Yixin Zhu, and
Song-Chun Zhu
|
|
|
|
|
Chi Zhang,
Baoxiong Jia,
Feng Gao,
Yixin Zhu,
Hongjing Lu, and
Song-Chun Zhu
|
|
|
|
|
Xu Xie,
Hangxin Liu,
Zhenliang Zhang,
Yuxing Qiu,
Feng Gao,
Siyuan Qi,
Yixin Zhu, and
Song-Chun Zhu
*Equal contributors
|
|
|
|
|
Yixin Zhu*,
Chenfanfu Jiang*,
Yibiao Zhao,
Demetri Terzopoulos, and
Song-Chun Zhu
*Equal contributors
|
|
|
|
|
Wenhe Zhang,
Chi Zhang,
Yixin Zhu,
Song-Chun Zhu
|
|
|
|
|
Yixin Zhu*,
Yibiao Zhao*, and
Song-Chun Zhu
*Equal contributors
|
|
|
|
|
Arjun Akula,
Shuai Wang, and
Song-Chun Zhu
|
|
|
|
|
Mark Edmonds*,
Feng Gao*,
Hangxin Liu*,
Xu Xie*,
Siyuan Qi,
Brandon Rothrock,
Yixin Zhu,
Ying Nian Wu,
Hongjing Lu, and
Song-Chun Zhu
*Equal contributors
|
|
|
|
|
Chi Zhang*,
Feng Gao*,
Baoxiong Jia,
Yixin Zhu, and
Song-Chun Zhu
|
|
|
|
|
Jenny Lin*,
Xingwen Guo*,
Jingyu Shao*,
Chenfanfu Jiang,
Yixin Zhu, and
Song-Chun Zhu
*Equal contributors
|
|
|
|
|
Xiaofeng Gao,
Ran Gong,
Tianmin Shu,
Xu Xie,
Shu Wang,
and Song-Chun Zhu
|
|
|
|
|
Tianmin Shu,
M. S. Ryoo, and
Song-Chun Zhu
|
|
|
|
|
Siyuan Qi,
Yixin Zhu,
Siyuan Huang,
Chenfanfu Jiang, and
Song-Chun Zhu
|
|
|
Cognition: Functionality, Physics, Intentionality, Causality, Value
|
|
Sirui Xie*,
Feng Gao*, and
Song-Chun Zhu
*Equal contributors
|
|
|
|
|
Mark Edmonds,
Xiaojian Ma,
Siyuan Qi,
Yixin Zhu,
Hongjing Lu, and
Song-Chun Zhu
|
|
|
|
|
Mark Edmonds*,
Siyuan Qi,
Yixin Zhu,
James Kubricht,
Song-Chun Zhu, and
Hongjing Lu
*Equal first author
|
|
|
|
|
James Kubricht*,
Yixin Zhu*,
Chenfanfu Jiang*,
Demetri Terzopoulos,
Song-Chun Zhu, and
Hongjing Lu
*Equal first author
|
|
|
|
|
Tian Ye*,
Siyuan Qi*,
James Kubricht,
Yixin Zhu,
Hongjing Lu, and
Song-Chun Zhu
*Equal first author
|
|
|
|
|
Jungseock Joo,
Weixin Li,
Francis Steen, and
Song-Chun Zhu
|
|
|
|
|
Amy Fire, and
Song-Chun Zhu
|
|
|
|
|
Amy Fire, and
Song-Chun Zhu
|
|
|
|
|
Mingtao Pei,
Yunde Jia, and
Song-Chun Zhu
|
|
|
|
|
Dan Xie,
Sinisa Todorovic, and
Song-Chun Zhu
|
|
|
|
|
Xinlei Wang*,
Yuxing Qiu*,
Stuart R. Slattery,
Yu Fang,
Minchen Li,
Song-Chun Zhu,
Yixin Zhu,
Min Tang,
Dinesh Manocha, and
Hongjing Lu
*Equal contributors
|
|
|
|
|
Tao Yuan,
Hangxin Liu,
Lifeng Fan,
Zilong Zheng,
Tao Gao,
Yixin Zhu, and
Song-Chun Zhu
|
|
|
|
|
Mark Edmonds*,
James Kubricht*,
Colin Summers,
Yixin Zhu,
Brandon Rothrock,
Song-Chun Zhu, and
Hongjing Lu
*Equal first author
|
|
|
|
|
James Kubricht*,
Yixin Zhu*,
Wei Liang,
Song-Chun Zhu,
Chenfanfu Jiang, and
Hongjing Lu
*Equal first author
|
|
|
|
|
James Kubricht*,
Chenfanfu Jiang*,
Yixin Zhu*,
Song-Chun Zhu,
Demetri Terzopoulos, and
Hongjing Lu
*Equal first author
|
|
|
|
|
Wei Liang,
Yibiao Zhao,
Yixin Zhu, and
Song-Chun Zhu
|
|
|
|
|
Bo Zheng*,
Yibiao Zhao*,
Joey C. Yu,
Katsushi Ikeuchi, and
Song-Chun Zhu
(*equal contribution)
|
|
|
|
|
Yibiao Zhao, and
Song-Chun Zhu
|
|
|
|
|
Bo Zheng,
Yibiao Zhao,
Joey C. Yu,
Katsushi Ikeuchi, and
Song-Chun Zhu
|
|
|
Robotics: Task and Motion Planning, Robot Perception, Sensoring
|
|
Ziyuan Jiao*,
Zeyu Zhang*,
Weiqi Wang,
David Han,
Song-Chun Zhu
Yixin Zhu, and
Hangxin Liu,
*Equal contributors
|
|
|
|
|
Shuwen Qiu*,
Hangxin Liu*,
Zeyu Zhang,
Yixin Zhu, and
Song-Chun Zhu
*Equal contributors
|
|
|
|
|
Xu Xie,
Changyang Li,
Chi Zhang,
Yixin Zhu, and
Song-Chun Zhu
|
|
|
|
|
Hangxin Liu*,
Zeyu Zhang*,
Yixin Zhu, and
Song-Chun Zhu
*Equal contributors
|
|
|
|
|
Hangxin Liu*,
Yaofang Zhang*,
Wenwen Si,
Xu Xie,
Yixin Zhu, and
Song-Chun Zhu
*Equal contributors
|
|
|
|
|
Mark Edmonds*,
Feng Gao*,
Xu Xie,
Hangxin Liu,
Siyuan Qi,
Yixin Zhu,
Brandon Rothrock, and
Song-Chun Zhu
*Equal contributors
|
|
|
|
|
Tianmin Shu,
Xiaofeng Gao,
Michael S. Ryoo, and
Song-Chun Zhu
|
|
|
|
|
Caiming Xiong,
Nishant Shukla,
Wenlong Xiong, and
Song-Chun Zhu
|
|
|
|
|
Caiming Xiong,
Nishant Shukla,
Pablo Garcia Kilroy,
Mun Wai Lee, and
Song-Chun Zhu
|
|
|
|
|
Ziyuan Jiao*,
Zeyu Zhang*,
Xin Jiang,
David Han,
Song-Chun Zhu
Yixin Zhu, and
Hangxin Liu,
*Equal contributors
|
|
|
|
|
Zhenliang Zhang,
Yixin Zhu, and
Song-Chun Zhu
|
|
|
|
|
Mark Edmonds*,
Feng Gao*,
Hangxin Liu*,
Xu Xie*,
Siyuan Qi,
Brandon Rothrock,
Yixin Zhu,
Ying Nian Wu,
Hongjing Lu, and
Song-Chun Zhu
*Equal contributors
|
|
|
|
|
Tao Yuan,
Hangxin Liu,
Lifeng Fan,
Zilong Zheng,
Tao Gao,
Yixin Zhu, and
Song-Chun Zhu
|
|
|
|
|
Zeyu Zhang,
Hangxin Liu,
Ziyuan Jiao,
Yixin Zhu, and
Song-Chun Zhu
|
|
|
|
|
Hangxin Liu*,
Zhenliang Zhang*,
Xu Xie,
Yixin Zhu,
Yue Liu,
Yongtian Wang, and
Song-Chun Zhu
*Equal contributors
|
|
|
|
|
Hangxin Liu,
Chi Zhang,
Yixin Zhu, and
Song-Chun Zhu
|
|
|
|
|
Xu Xie*,
Hangxin Liu*,
Mark Edmonds,
Feng Gao,
Siyuan Qi,
Yixin Zhu,
Brandon Rothrock, and
Song-Chun Zhu
*Equal contributors
|
|
|
|
|
Hangxin Liu*,
Xu Xie*,
Matt Millar*,
Mark Edmonds,
Feng Gao,
Yixin Zhu,
Veronica Santos,
Brandon Rothrock, and
Song-Chun Zhu
*Equal contributors
|
|
Vision: Parsing Objects, Scenes and Events
|
|
Siyuan Huang,
Yixin Chen,
Tao Yuan
Siyuan Qi,
Yixin Zhu, and
Song-Chun Zhu
|
|
|
|
|
Yixin Chen*,
Siyuan Huang*,
Tao Yuan
Siyuan Qi,
Yixin Zhu, and
Song-Chun Zhu
|
|
|
|
|
Siyuan Huang,
Siyuan Qi,
Yinxue Xiao,
Yixin Zhu,
Ying Nian Wu,and
Song-Chun Zhu
|
|
|
|
|
Siyuan Huang,
Siyuan Qi,
Yixin Zhu,
Yinxue Xiao,
Yuanlu Xu,and
Song-Chun Zhu
*Equal contributors
|
|
|
|
|
Wei Liang,
Yixin Zhu, and
Song-Chun Zhu
|
|
|
|
|
Wei Liang,
Yibiao Zhao,
Yixin Zhu, and
Song-Chun Zhu
|
|
|
|
Quanshi Zhang,
Ying Nian Wu, and
Song-Chun Zhu
|
|
|
|
Tianfu Wu, and
Song-Chun Zhu
|
|
|
|
Ping Wei,
Yibiao Zhao,
Nanning Zheng, and
Song-Chun Zhu
|
|
|
|
|
Xi Song,
Tianfu Wu,
Yunde Jia, and
Song-Chun Zhu
|
|
|
|
|
Shuo Wang,
Jungseock Joo,
Yizhou Wang, and
Song-Chun Zhu
|
|
|
|
|
Mohamed R. Amer,
Dan Xie,
Mingtian Zhao,
Sinisa Todorovic, and
Song-Chun Zhu
|
|
|
|
|
Brandon Rothrock, and
Song-Chun Zhu
|
|
|
|
|
Baoxiong Jia,
Yixin Chen,
Siyuan Huang,
Yixin Zhu, and
Song-Chun Zhu
|
|
|
|
|
Tao Yuan,
Hangxin Liu,
Lifeng Fan,
Zilong Zheng,
Tao Gao,
Yixin Zhu, and
Song-Chun Zhu
|
|
|
|
|
Chenfanfu Jiang*,
Yixin Zhu*,
Siyuan Qi*,
Siyuan Huang*,
Lap-Fai Yu,
Demetri Terzopoulos, and
Song-Chun Zhu
*Equal contributors
|
|
|
|
|
Amy Fire, and
Song-Chun Zhu
|
|
|
|
|
Tianmin Shu,
Dan Xie,
Brandon Rothrock,
Sinisa Todorovic, and
Song-Chun Zhu
|
|
|
|
|
Jifeng Dai,
Ying Nian Wu,
Jie Zhou, and
Song-Chun Zhu
|
|
|
|
|
Jungseock Joo,
Shuo Wang, and
Song-Chun Zhu
|
|
|
|
|
Tianfu Wu, and
Song-Chun Zhu
|
|
|
|
|
Yibiao Zhao, and
Song-Chun Zhu
|
|
|
|
|
Z. Han,
Z. Xu, and
S.-C. Zhu
|
|
|
|
|
Jinli Suo,
Song-Chun Zhu,
Shiguang Shan, and
Xilin Chen
|
|
|
|
|
Jacob Porway,
Qiongchen Wang, and
Song-Chun Zhu
|
|
|
|
|
Hang Qi,
Tianfu Wu,
Mun Wai Lee, and
Song-Chun Zhu
|
|
|
Language: Joint Parsing, Grounding, Alignment, Communication
|
|
Liang Qiu,
Yuan Liang,
Yizhou Zhao,
Pan Lu,
Baolin Peng,
Zhou Yu,
Ying Nian Wu, and
Song-Chun Zhu
|
|
|
|
|
Arjun Akula,
Spandana Gella,
Yaser Al-Onaizan,
Siva Reddy, and
Song-Chun Zhu
|
|
|
|
|
Changsong Liu,
Joyce Y. Chai,
Nishant Shukla, and
Song-Chun Zhu
|
|
|
|
|
Jungseock Joo,
Fancis F. Steen
Song-Chun Zhu
|
|
|
|
|
Kewei Tu, Meng Meng,
Mun Wai Lee,
Tae Eun Choe, and
Song-Chun Zhu
|
|
|
|
|
Weixin Li,
Jungseock Joo,
Hang Qi, and
Song-Chun Zhu
|
|
|
|
|
Liang Qiu,
Yizhou Zhao,
Jinchao Li,
Pan Lu,
Baolin Peng,
Jianfeng Gao,
and Song-Chun Zhu
|
|
|
|
|
Liang Qiu,
Yizhou Zhao,
Weiyan Shi,
Yuan Liang,
Feng Shi,
Yuan Tao,
Zhou Yu, and
Song-Chun Zhu
|
|
|
|
|
Arjun Akula, and
Song-Chun Zhu
|
|
|
|
|
Qing Li ,
Siyuan Huang,
Yining Hong,
Yixin Chen,
Ying Nian Wu, and
Song-Chun Zhu
|
|
|
|
|
Luyao Yuan,
Zipeng Fu,
Jingyue Shen,
Lu Xu,
Juhong Shen, and
Song-Chun Zhu
|
|
|
|
|
Benjamin Yao, Xiong Yang, Liang Lin,
Mun Wai Lee, and
Song-Chun Zhu
|
|
|
Learning: Statistics, Causality, Utility
|
|
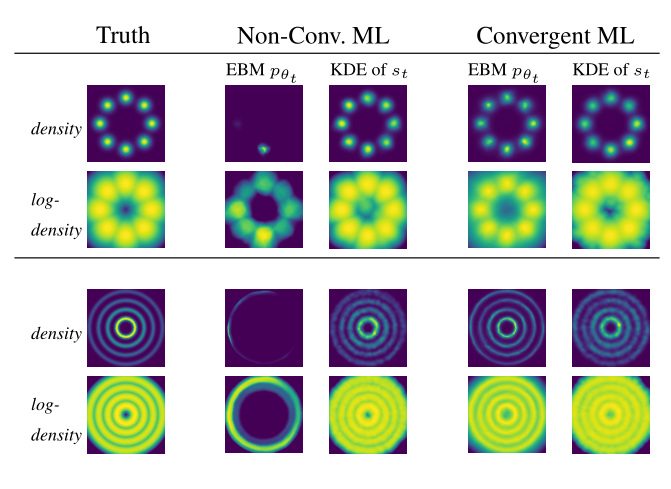
Erik Nijkamp*,
Bo Pang*,
Tian Han,
Song-Chun Zhu, and
Ying Nian Wu
*Equal contributors
|
|
|
|
|
Ruiqi Gao*,
Yang Lu*,
Junpei Zhou,
Song-Chun Zhu, and
Ying Nian Wu
*Equal contributors
|
|
|
|
|
Jianwen Xie*,
Yang Lu*,
Song-Chun Zhu, and
Ying Nian Wu
|
|
|
|
|
Erik Nijkamp*,
Mitch Hill*,
Tian Han,
Song-Chun Zhu, and
Ying Nian Wu
|
|
|
|
|
Tian Han*,
Erik Nijkamp*,
Xiaolin Fang,
Mitchell Hill,
Song-Chun Zhu, and
Ying Nian Wu
|
|
|
|
|
Adrian Barbu, Maria Pavlovskaia, and
Song-Chun Zhu
|
|
|
|
|
Jianwen Xie,
Wenze Hu,
Song-Chun Zhu, and
Ying Nian Wu
|
|
|
|
|
Jianwen Xie,
Yang Lu,
Song-Chun Zhu, and
Ying Nian Wu
|
|
|
|
|
Yi Hong, Zhangzhang Si, Wenze Hu,
Song-Chun Zhu, and
Ying Nian Wu
|
|
|
|
|
Tian Han,
Yang Lu,
Song-Chun Zhu, and
Ying Nian Wu
|
|
|
|
|
Jianwen Xie,
Yang Lu,
Song-Chun Zhu, and
Ying Nian Wu
|
|
|
|
|
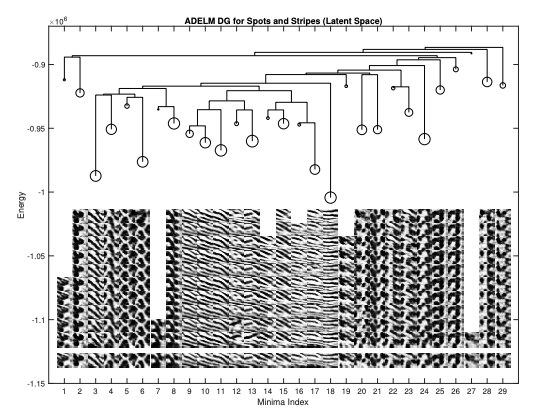
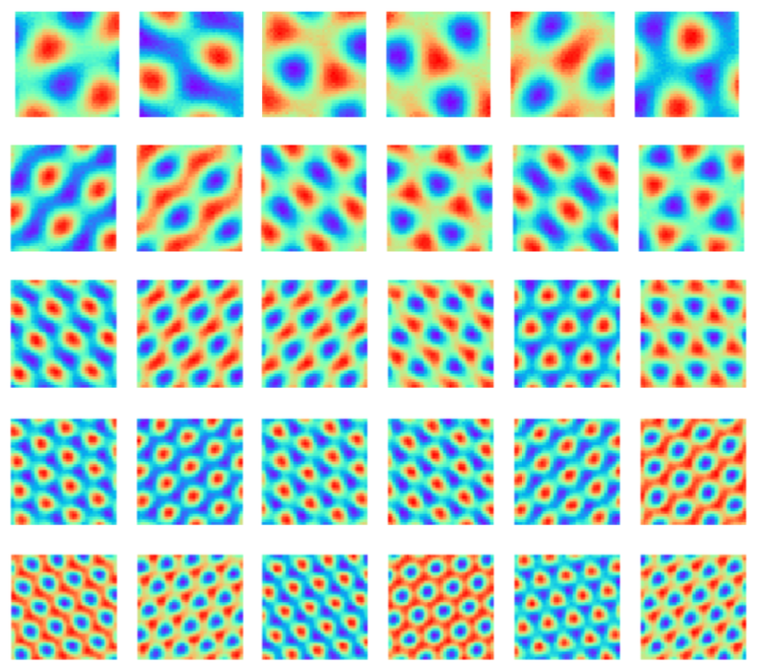
Mitch Hill,
Erik Nijkamp, and
Song-Chun Zhu
|
|
|
|
|
Jianwen Xie*,
Zilong Zheng*,
Ruiqi Gao,
Wenguan Wang,
Song-Chun Zhu, and
Ying Nian Wu
|
|
|
|
|
Ruiqi Gao*,
Jianwen Xie*,
Song-Chun Zhu, and
Ying Nian Wu
|
|
|
|
|
Jianwen Xie*,
Ruiqi Gao*,
Zilong Zheng,
Song-Chun Zhu, and
Ying Nian Wu
|
|
|
|
|
Jianwen Xie*,
Ruiqi Gao*,
Zilong Zheng,
Song-Chun Zhu, and
Ying Nian Wu
|
|
|
|
|
Jianwen Xie,
Song-Chun Zhu, and
Ying Nian Wu
|
|
|
|
|
Erik Nijkamp,
Mitchell Hill,
Song-Chun Zhu, and
Ying Nian Wu
|
|
|
|
|
Benjamin Z. Yao, and
Song-Chun Zhu
|
|
|