Video Primal Sketch Z. Han, Z. Xu and S.-C. Zhu, "Video Primal Sketch: A Generic Middle-Level Representation of Video,"Int'l Conf. on Computer Vision, Barcelona, 2011. [pdf] |
|||
| |||
Problem statementVideos of natural scenes contain vast varieties of motion patterns. Fig. 2 shows some examples of different components in video. The simplest are sketchable and trackable motions, such as trackable corners, lines, and feature points, whose positions and shapes can be tracked during the movement. The most complex are textured motions, such as water, fire or grass. Essentially, these motion patterns can be classified based on their complexities measured by two criteria: i) sketchability, i.e. the possibility for representing a local patch by an explicit image primitive, and ii) trackability, i.e. the uncertainty of tracking an image patch using the entropy of posterior probability over velocities. |
|||
 |
|||
Fig. 2 Four types of video phenomenon.
|
|||
 |
|||
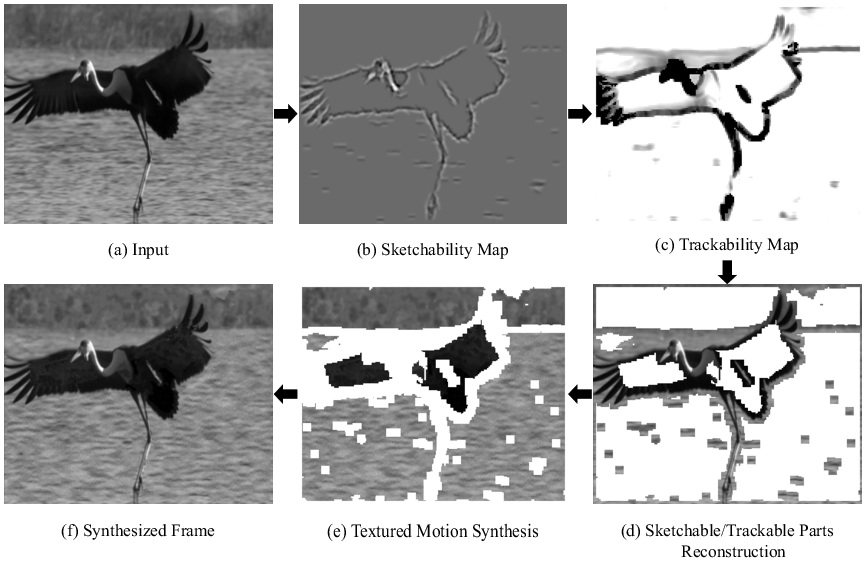
Fig. 3 Outline of Video Primal Sketch. (a) Input. (b) Sketchability map represented by filters. (c) Trackability map where heavier color means more trackable. (d) Reconstruction of explicit regions. (e) Synthesis for implicit regions (textured motions). (f) Synthesized frame by integrating explicit and implicit representations seamlessly.
|
|||
 |
|||
Table. 1 Parameters of Video Primal Sketch.
|
|||
As an extension of Primal Sketch to videos, we study a generic representation, called Video Primal Sketch (VPS), by integrating two regimes, sketchable or trackable parts with exlicit representation and non-sketchable and intrackable parts with implicit representation. Our goal is not only simply providing a parsimonious model for video compression and coding, but more importantly, it may support high level tasks such as motion tracking and action recognition. Fig. 3 and Table. 1 shows an example. An input frame from a video in (a) is separated into sketchable and non-sketchable areas by the sketchability map in (b), and trackable parts and intrackable regions by the trackability map in (c). Explicit regions including sketchable or trackable parts are modeled by a sparse coding model and reconstructed with motion primitives in (d), and each implicit region of non-sketchable and intrackable parts has a textured motion which is synthesized by a generalized FRAME model in (e). The synthesis in (f) of this frame integrates the results from (d) and (e) seamlessly. The explicit representations are modeled with 3,600 parameters and the implicit representations are modeled with 420 parameters, which shows the parsimonious property of the model. |
|||
Explicit Representation by Sparse Coding
The explicit region of a video is decomposed into about hundreds of disjoint domains Each domain define a brick, a spatio-temporal volume in the video, which can be represented by a motion primitive
The primitives are chosen from a dictionary as shown in Fig. 3(a). Here i indexes the parameters of the primitive, such as type, profile, position and velocity. Then the probablistic model for explicit region is given by
Fig. 4 shows some examples of reconstruction by motion primitives. In each group, the original local image, the filter that is supposed to fit, the generated primitive and the motion velocity are given. In the frame, each patch is marked by a square with a short line for representing its motion information. | |||

|
|||
Fig. 4 Dictionary of motion primitives (a) and spatio-temporal filters (b).
|
|||
 |
|||
Fig. 4 Examples of primitives.
|
|||
Implicit Representation by Spatio-temporal FRAME (ST-FRAME)The implicit region of a video can be segmented into a little number of disjoint homogeneous textured motion regions,
Each region is defined by a Julesz ensemble which is an equivalence class of videos,
h is a series of filter responses histograms, which charactorize the macroscopic properties of the textured motion pattern, and the filters are chosen from a dictionary of spatio-temporal filters as shown in Fig. 3(b). The effectiveness of each kind of filters is shown in Fig. 5. Following the FRAME model, the statistical model of one pattern of textured motion can be written in the form of the following Gibbs distribution,
Fig. 6 shows some results of textured motion synthesis. |
|||
 |
|||
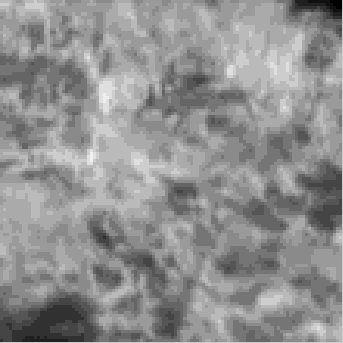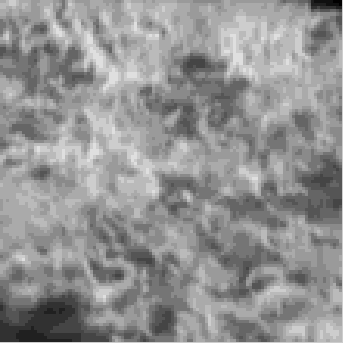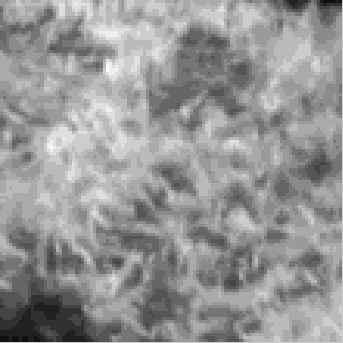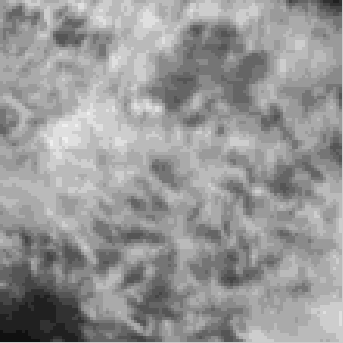
Fig. 5 Synthesis for one frame of the ocean textured motion.
(f) is
one frame from textured motion of ocean. Starting from a
white noise frame in (a), (b) is synthesized with only 7 static
filters. It shows high smoothness in spatial domain, but
lacks temporal continuity with previous frames. However,
in (c) the synthesis with only 9 motion filters has similar
macroscopic distribution to the observed frame, but appears
quite grainy over local spatial relationship. By using both
static and motion filters, the synthesis in (d) performs well
on both spatial and temporal relationships. Compared with
(d), the synthesis by 2 extra flicker filters in (e), shows more
smoothness and more similar to the observed frame.
|
|||
|
|
|||
Fig. 6 Texture synthesis.
|
|||
Hybrid Model for Video RepresentationIn summary, by taking the explicit parts as boundary conditions for the implicit regions, the probabilistic models for video primal sketch representation is given by
We denote by VPS=(B,H) as the representation for the video, where H are the histograms described by F. The solution of VPS is obtained by maximizing the posterior probability
The algorithm is given as follows
Fig. 7 shows three examples of video synthesis by VPS. The color space is YCbCr. | |||
|
|
|||
Fig. 7 Synthesis for videos.
|
|||
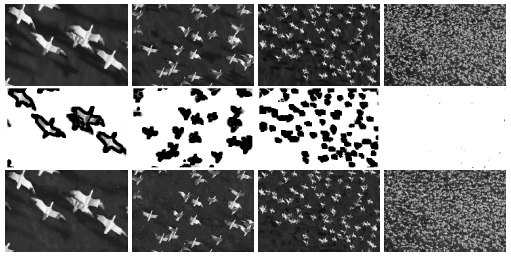
Extensions of VPSVPS over scales, densities, dynamics: The optimal visual representation at a region is affected by distance, density and dynamics. In Fig. 8 ,As the scale changes from high to low over time, the birds in the videos are perceived by lines of boundary, groups of kernels, dense points and dynamic textures respectively. |
|||
 |
|||
Fig. 8 VPS over scales.
|
|||
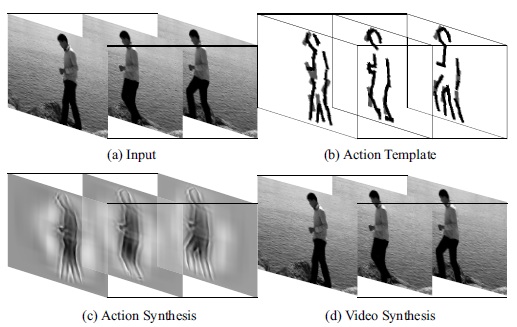
VPS supports high-level representation: VPS is also compatible with high-level action representation. By grouping meaningful explicit parts in a principled way, it will represent an action template. In Fig. 9 , (b) is the action template given by the deformable action template model from the video shown in (a). (c) shows a rough action synthesis with only filters from a matching pursuit process. While in (d), following the VPS model, the action parts and a few sketchable background are reconstructed by the explicit representation, and the large region of water is synthesized by the implicit representation; thus we get the synthesis of the whole video. |
|||
Fig. 9 VPS supports high-level representation.
|
|||
Discussion and Future WorkVPS is compatible with high-level representations, e.g. action recognition where the popular features are HOG (Histogram of Oriented Gradients) for appearance and HoF (Histogram of Optical-flow) for motion. Specifically, sketchability and trackability in VPS provide spatial and temporal statistical information of the video respectively as the HOG and HoF features do. The difference is that VPS moves one step further by making local decisions to represent those regions, which have low entropy in their appearance or motion statistics, with explicit primitives. In future works, we will learn a richer dictionary of the video primitives and improve the model by adding histograms of velocities as a stronger temporal constraint, which is consistent with the concept of trackability. This will hopefully give better time-continuity over frames in video synthesis and be used for action recognition and representation in the high level. |
|||
|



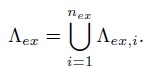
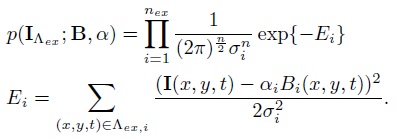
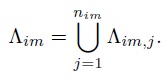
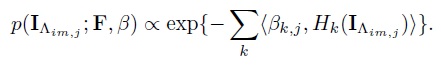






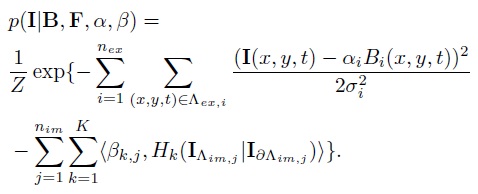







|
Maintained by Zhi Han. Last update
08/08/2011. |