Parsing Video Events with Goal Inference and Intent Prediction [mirror site]
[Dataset Download]M.Pei, Y. Jia, and S.-C. Zhu, Parsing Video Events with Goal Inference and Intent Prediction, ICCV Spain 2011.
Overview
In this paper, we present an event parsing algorithm based on Stochastic Context Sensitive Grammar (SCSG) for understanding events, inferring the goal of agents, and predicting their plausible intended actions. The SCSG represents the hierarchical compositions of events and the temporal relations between the sub-events. The alphabets of the SCSG are atomic actions which are defined by the poses of agents and their interactions with objects in the scene. The temporal relations are used to distinguish events with similar structures, interpolate missing portions of events, and are learned from the training data. In comparison with existing methods, our paper makes the following contributions. i) We define atomic actions by a set of relations based on the fluents of agents and their interactions with objects in the scene. ii) Our algorithm handles events insertion and multi-agent events, keeps all possible interpretations of the video to preserve the ambiguities, and achieves the globally optimal parsing solution in a Bayesian framework; iii) The algorithm infers the goal of the agents and predicts their intents by a top-down process; iv) The algorithm improves the detection of atomic actions by event contexts. We show satisfactory results of event recognition and atomic action detection on the data set we captured which contains 12 event categories in both indoor and outdoor videos.
Atomic actions' definition
Atomic actions are defined by a set of relations based on the fluents of agents and their interactions with objects in the scene. Two types relations are used in our paper: unary relations (fluents) and binary relations. Figure 1 and Figure 2 show the unary and binary relations. Figure 3 shows some sample atomic actions.
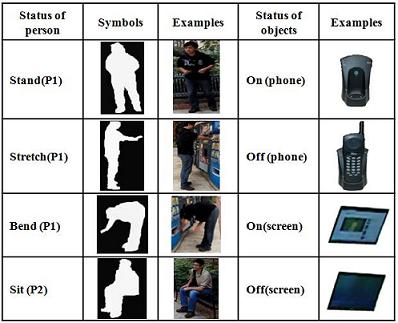
Figure 1 Unary relations
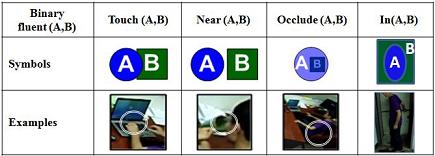
Figure 2 Binary realtions
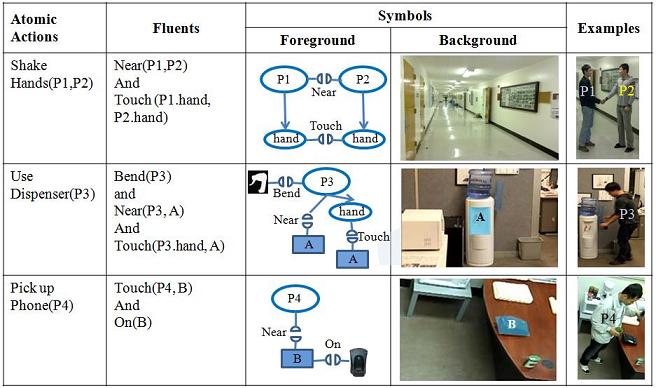
Figure 3 Some sample atomic actions
Event representation by AoG
Event is a series of atomic actions and is representated by SCSG which is embodied in an AoG. The AoG represents the hierarchical compositions of events and the temporal relations between the sub-events (atomic actions).Figure 4 shows the AoG of events in an office scene. Table 1 shows the atomic actions used in the office scene.
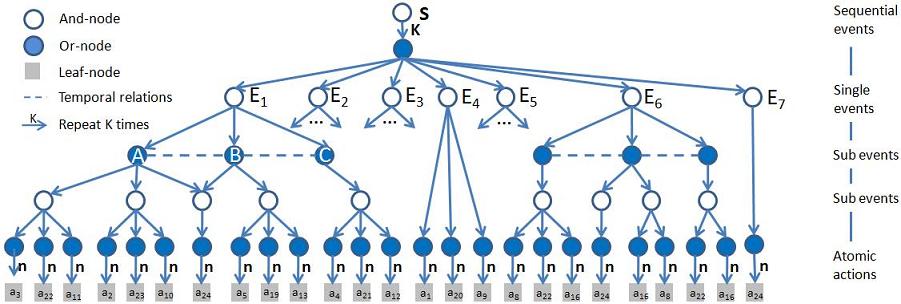
Figure 4 AoG of events in an office scene
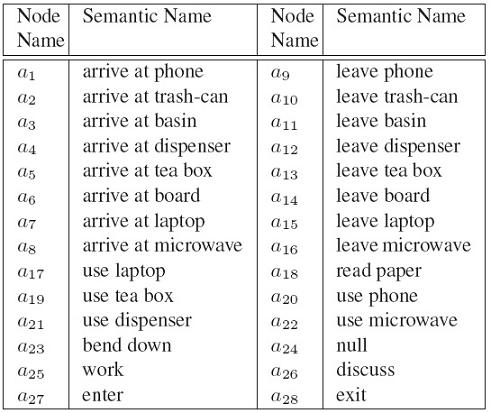
Table 1 The atomic action in the office scene which are the terminal nodes in AoG representation.
Event Parsing
As there are ambiguities in the input, given a video, there will be multi interpretations. Each interpretation will segment the video into events in the high level and atomic actions in the low level. Figure 5 uses a small AoG to show the idea. Figure 6 shows the process of generating parse graphs. We use decision moments(time points at which the number of acceptable interpretations drops sharply) to reduce the complexity of our algorithm, as shown in Figure 7.
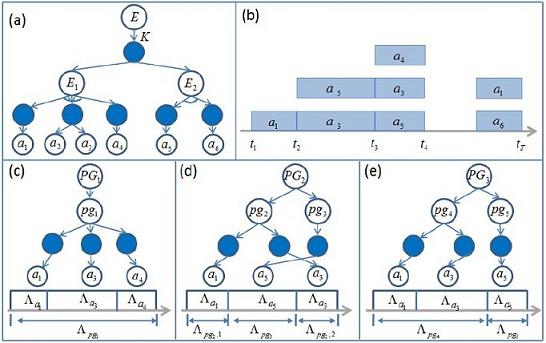
Figure 5 (a) A small AoG. (b) A typical input of the algorithm.
(c),(d) and (e) are three possible parse graphs (interpretations)
of the input video
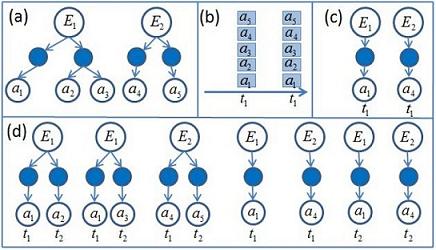
Figure 6(a) The two AoGs of single event E1 and E2. (b) The
input in the worst case. (c) The parse graphs at time t1. (d) The
parse graphs at time t2
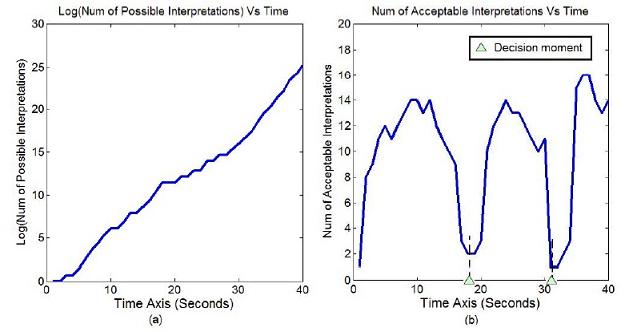
Figure 7 (a) The number of possible interpretations (in logarithm)
vs time (in seconds). (b) The number of acceptable interpretations
vs time. The decision moments are the time points on which the number of acceptable interpretations
drops sharply.
Experiments
For evaluation, we collect videos in 5 indoor and outdoor scenes, include office, lab, hallway, corridor and around vending machines. We test our algorithm on the data. Figure 8 shows the ROC curve of recognition results of atomic actions with and without event context. Figure 9 shows the recognition results of event which involve multiple agents. Figure 10 shows the experiment results of event segmentation, insertion, goal inference and intent prediction.
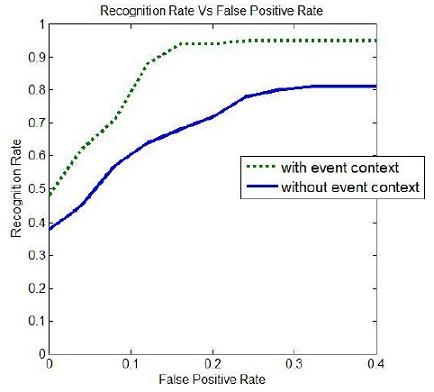
Figure 8 The ROC curve of recognition results of atomic actions.
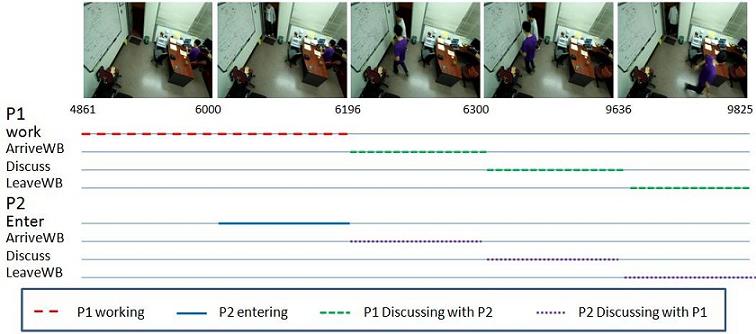
Figure 9 Experiment results of event recognition which involve
multiple agents. Agent P1 works during frames 4861 to 6196,
agent P2 enters the room from frames 6000 to 6196, then they go
to the white board, have a discussion and leave the board.
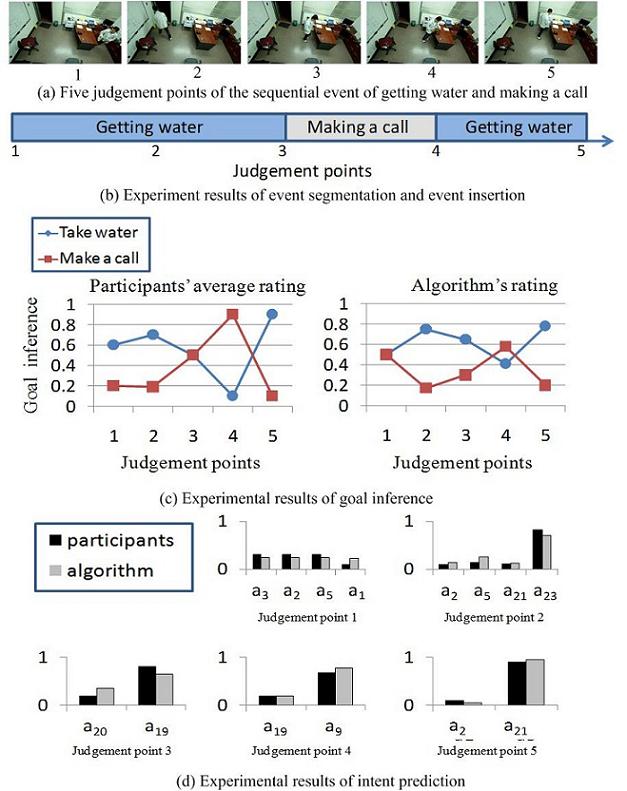
Figure 10 Experiment results of event segmentation, insertion, goal inference and intent prediction.
Paper

Demo

Some video data





Video_1
Last Updated: August 2011